CAM - CVPR 2015
Learning Deep Features for Discriminative Localization
弱监督对象定位 - 仅提供Image level label
期望:每个单元被其感受野内的某种视觉模式激活。因此 fk (表示空间位置 (x, y) 处最后一个卷积层中单元 k 的激活//输出特征图的一个像素)是该视觉模式存在的地图。类激活图只是这些视觉模式在不同空间位置的存在的加权线性和
计算卷积特征图对于特定输出单元的重要性来实现的
⭐⭐⭐网络可以保留其卓越的定位能力,直到最后一层 => 深层特征的定位能力
❗❗❗尽管接受了图像级标签的训练,CNN 仍具有出色的对象定位能力
缺陷:卷积特征图→全局平均池化→softmax层 // 特定网络结构
在卷积特征图上执行全局平均池化,并将它们用作全连接层的特征,产生所需的输出分类;
❗❗❗将输出层的权重投影回卷积特征图来识别图像区域的重要性
Grad-CAM - ICCV 2017
适用CNN模型
但论文提到在CNN+LSTM的也能定位有区别的图像区域
α 捕获特征图 k 对于目标类 c 的重要性 // 与CAM的分类线性层权重作用一致
ReLU的作用,只对对感兴趣的类别有积极影响的特征感兴趣。负像素可能属于图像中的其他类别
上述操作 => 具有类别区分性并且可以很好地定位相关图像区域 - 最后特征图比较小!
但缺乏显示细粒度重要性的能力 (能区分猫狗,但对为什么识别为猫,不够精确)
通过点乘法融合 引导反向传播 和 Grad-CAM => 可视化
Grad-CAM : 类别区分性
Guided Backprop: 细节纹理重要程序。 做法:将梯度值小于等于零的部分置为零,保留梯度值大于零的部分 => 以突出输入图像中对预测结果有积极影响的区域,来实现对神经网络中每个像素对最终预测结果的影响进行可视化和解释
浅层卷积关注纹理特征,深层网络关注本质的那种特征?
DETR - ECCV 2020
⭐End-to-End⭐ Object Detection with Transformers
传统:设置锚框 + 非极大值抑制(去除多余的框)
创新:集合预测(预测分类 + 锚框)
CNN backbone - local information fusion
Transformer encoder - global information fusion
object queries - learnable information vector 作用: => anchor
FFN: 1. classification => output class vector 2. box => output 4 number [center_x, center_y, width, hight]
object queries: 作用就是锚框,并且一次性生成100个 » 图片检测的物体数
如何将object queries 与 groundtrue一一对应?
匈牙利算法 寻找最佳匹配
匹配loss = 分类loss(分类正确率) + 框loss(框的重叠度)
=> 匈牙利算法 => 哪些框与GT最佳匹配(预测框与GT一一对应)
最终回传梯度优化参数LOSS = 分类loss(分类正确率) + [框loss + 与框大小无关的iou loss]
因为框也是生成的,且Transformer容易出大框(全局建模)
Bert - 2018
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding - Computation and Language
Bidirectional Transformers 意思是
Transformer Encoder中的自注意力计算是全局的,每个Token能观测到其余的Token序列; 而
Transformer Decoder中由于进行的是Masked Multi Head Self Attention,所以序列只能观测到自己与之前的语境;
这对于文本上下文语境建模是有弊端的!
(生成式无监督学习)
总体结构
[CLS] 分类Token,凝聚全局语义信息
[SEP] 分割符,划分句子范围
用的某个语料库进行词嵌入
⭐训练方法
-
完型填空:使某个词随机被 [Mask] 字符遮挡;为防止模型对[Mask]字符敏感,遮挡时使用概率遮挡 => 1. 仍替换为[Mask]字符 2.随机替换为其他字符 3. 保持不变 => 迫使模型学习上下文语境 [句子内信息建模]
-
预测下一句: [句子间信息建模]
丰富的上下文信息:通过考虑单词的左右上下文,BERT 能够更好地理解词义和句法结构,这对于理解语言的复杂性至关重要。
GPT
generative pretrain transformer
初略版
模型图:(Transformer Decoder -仅Masked Attention版)
⭐ input: word => index(查找词汇表) => embedding + position embedding
[batch, sequence_length, embedding_dim] # sequence_length 可由多个句子组成,可以使用<s>标识句子结束,<pad>用来填充,使得sequence_length在batch内长度一致
⭐ train:
x1 => x2
x1, x2 => x3
x1, x2, x3 => x4
因为每个词都要预测下一个词,故使用masked attention (mask-softmax),防止答案泄漏
CLIP - 2021
Learning Transferable Visual Models From Natural Language Supervision
实现zero-shot,上游大数据集预训练好,下游任务迁移学习无需样本微调
多模态模型的总体目标就是:训练一个模型,一方面能统一特征表达,另一方面又能让不同模态特征间学到相关性
(判别式无监督学习)
工作目的
痛点:
-
在特点数据集上进行标签训练 => 输入没见过的类别,那么模型就不能输出正确的结果
-
数据出现分布偏移,动物图片与卡通动物图片 => 识别不出来
图片 - 文字描述 , 模型学习配对关系
一个对象的不同视角表示:图片和文本描述
对比学习方法 (Train)
- Text Encoder (resnet/vit) 学习文本描述的 深度特征 - 单模态内特征 // T_i == 一个文本特征
- Image Encoder(transformer) 学习图片的 深度特征 - 单模态内特征 // I_i == 一个图像特征
- 将多模态特征投影到跨模态空间 // 矩阵映射,(特征向量)到同一纬度
- 计算余弦相似度,很明显,正确配对的位置为对角线
- 计算Loss: (相似度logit作为预测分数)
- 按行计算Loss,在每一行范围内做softmax,然后计算cross_entropy(蓝色格子部分是真值)。这样计算Loss的意义是:对于每一张图片,我们都希望找到和它最相似的文字
- 按列计算Loss,在每一列的范围内做softmax,然后计算cross_entropy(蓝色格子部分是真值)。这样计算Loss的意义是:对于每一段文字,我们都希望找到和它最相似的图片
- 最后将这两个Loss相加取平均,代表我们在模型优化过程中考虑了“图片->文字”和“文字->图片”的双向关系
encoder均从头开始训练
预测
- 创建一个标签全集, [f’A photo of a {object}’ for object in dataset_labels]
- Text Encoder 学习上述 模板文字描述 的 深度特征
- Image Encoder 学习 待预测图片 的 深度特征
- 计算余弦相似度 => 取最高分作为预测目标
缺点
- 每次预测需要构建标签全集描述
- 对抽象任务,性能较差
Two-Stream - 2014
Two-Stream Convolutional Networks for Action Recognition in Videos
⭐先前工作中通过使用堆叠视频帧作为网络的输入来解决此任务,但结果明显比最好的手工制作的浅层表示差。 => 这可能表明学习的时空特征不能很好地捕捉运动(简单堆叠 => 让模型从庞大的数据中学习❌很难) => 模型很难识别该类特征 => 预先处理成模型擅长的数据形式
❗❗❗虽然多帧信息很重要,但以适当的方式将其呈现给 ConvNet 也很重要(饱和)
信息显式建模 => 可以简化学习过程
创新点
- 空间流从静止视频帧执行动作识别
- 时间流以识别密集光流形式的运动动作
=> 贴合人类视觉:识别物体 + 识别运动 => ⭐[结果角度]表明两个识别流是互补的
光流:帧帧之间像素变化(描述运动变化的数据形式) | 水平方向和垂直方向 <= 有用的线索 (与魔改模型不一样的思路)
⭐⭐⭐此类输入明确描述了视频帧之间的运动 => 这使得识别更容易 => 因为网络不需要隐式估计运动 (显示建模)
可以从光流数据 => 时空局部特征 || 运动学特征 || 运动是使用光流位移场明确表示的
模型框架(双模态)
提高模型迁移能力 类似于CLIP的目的
考虑将两个数据集合并为一个,由于类集之间的交叉,这并不简单
=> 多任务学习 => 最后生成多个分类头,对应两个数据集分类。混合多个数据集进行实验
MOCO - CVPR 2020
Momentum Contrast for Unsupervised Visual Representation Learning
(判别式无监督学习)
目标:
1️⃣ 构建一个足够大的动态词典,包含足够多的负样本,使模型真能够学到判别式的特征; 在海量数据中学到真正的样本分布
2️⃣ 因为词典是动态变化的,为了使词典中的负样本特征尽可能的保持一致性(模型参数不同,时间维度上,得到的特征向量存在不一致性),提出动量更新 => 动量模型的缓慢更新确保了字典中的特征相对稳定,从而提供更一致的负样本,提升对比学习的效果。
$$ θ_{k} ←mθ_{k} + (1 −m)θ_{q} $$ m ∈ [0, 1) 是动量系数。论文中Query Encoder 和Key Encoder是一样配置架构的编码器。 目的,缓慢的更新Key Encoder,构建一个又大又一致的动态词典。
框架伪代码
pretext task : 实例判别任务。目标拉近正样本对在特征空间的距离,并使负样本对尽可能的远离。
1# f_q, f_k: encoder networks for query and key
2# queue: dictionary as a queue of K keys (CxK)
3# m: momentum
4# t: temperature
5f_k.params = f_q.params # initialize
6for x in loader: # load a minibatch x with N samples
7 x_q = aug(x) # a randomly augmented version
8 x_k = aug(x) # another randomly augmented version
9
10 q = f_q.forward(x_q) # queries: NxC
11 k = f_k.forward(x_k) # keys: NxC
12 k = k.detach() # no gradient to keys
13
14 # positive logits: Nx1
15 l_pos = bmm(q.view(N,1,C), k.view(N,C,1))
16
17 # negative logits: NxK
18 l_neg = mm(q.view(N,C), queue.view(C,K))
19
20 # logits: Nx(1+K)
21 logits = cat([l_pos, l_neg], dim=1)
22
23 # contrastive loss, Eqn.(1)
24 labels = zeros(N) # positives are the 0-th
25 loss = CrossEntropyLoss(logits/t, labels)
26
27 # SGD update: query network
28 loss.backward()
29 update(f_q.params)
30
31 # momentum update: key network
32 f_k.params = m*f_k.params+(1-m)*f_q.params
33
34 # update dictionary
35 enqueue(queue, k) # enqueue the current minibatch
36 dequeue(queue) # dequeue the earliest minibatch
两个不同视角的同一张图片为正样本对,不同图片为负样本对。
抽特征:q, k; 最大化q k相似且与负样本远离
更新Q_Encoder, 使用Q_Encoder参数更新K_Encoder,动量缓慢更新
无监督预训练后好,取Q_Encoder作为抽取特征骨干网络,冻结其参数,微调分类头,在进行泛化测试
MAE - CVPR2022
Masked Autoencoders Are Scalable Vision Learners
非对称掩码自动编码器;Encoder和Decoder架构可以不同
(生成式无监督学习)
CV领域的Bert
⭐NLP与CV的不同:
-
信息密度不同
-
NLP:句子信息语义很高,信息密度也高。(人类语言-事先浓缩过的信息)
-
视觉:信息很冗余,也没高级的语义(自然界),像素可以被相邻的重建恢复
-
-
恢复难度不一致
- 恢复高级语义单词和恢复像素级(低级语义)图片,难度也不一样。
框架:
Encoder:位置编码所有Patch都加上。但仅输入未被Mask的Patch。并且Mask比例很高(论文mask75%patch),迫使模型学到高维的特征,而非捷径。
Decoder:Mask Patch是自学习的向量,并且和Encoded Patch在位置上一致,再次添加位置信息。
简单实现(shuffle,截取前面的作为Encoder输入,后面Patch被Mask;再shuffle逆操作,将Encoded Patch和learnabel patch位置对齐组合好进行Decoder。再重建像素)
通过预测每个屏蔽补丁的像素值来重建输入。解码器的最后一层是线性投影,其输出通道的数量等于补丁中像素值的数量。
损失函数计算像素空间中重建图像和原始图像之间的均方误差。
问题:
预训练的输入中具有很大一部分掩码标记,而这在下游任务未损坏的图像中不存在。这种差距可能会降低部署的准确性。
自监督学习方法通常侧重于预训练的不同借口任务。
对比学习对两个或多个视图之间的图像相似性和相异性进行建模。
wav2vec 2.0 - NeurIPS 2020
wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations
时序信号版本的Bert
[自监督]学习通用特征 => 再微调任务头
(判别式无监督学习)
总体框架:
1️⃣ 原始信号[X] =CNN=> 浅在特征表示 [Z]
2️⃣ 浅在特征表示 [Z] =Transformer Encoder=> 全局上下文特征表示 [C]
3️⃣ 浅在特征表示 [Z] =量化器=> 对比目标[Q]
- 把原来连续的特征空间假设是d维,拆分成G个子空间(codebook),每个子空间维度是d/G。
- 然后分别在每个子空间里面聚类(K-mean什么的),一共获得V个中心和其中心特征。
- 每个类别的特征用其中心特征代替。
量化qt和对应ct
❌ Quantization module 部分不理解
Mask
随机起点,遮挡后面t个时间步
对比损失
包括 qt 和 K 个干扰项
❗❗❗理解不太清晰
Whisper - 2022 OpenAI
Robust Speech Recognition via Large-Scale Weak Supervision
大力出奇迹
模型结构
多任务训练
-
[英文口语=> 英文] 语音识别
-
[多语言口语 => 英文] 语音识别 +翻译
-
[多语言口语 => 对应语言文字] 语音识别
-
识别背景音(无内容声音)
⭐⭐⭐信号 => Log-Mel Spectrogram(频谱图)
音素
⭐⭐⭐数据集
680k小时,超大数据集。 在此基础上预训练,并且0样本迁移(无需特定任务微调)
CPC - Machine Learning 2018
Representation Learning with Contrastive Predictive Coding
Contrastive Predictive Coding - 无监督学习
通过预测未来,学习特征表示 (学习对(高维)信号不同部分之间的底层共享信息进行编码的表示 - 局部平滑度)
不预测原始信号,而是对高维嵌入依赖建模
(判别式无监督学习)
CPC框架
$$
g_{enc}: local\ feature\ learning\
g_{ar}: global\ context\ learning
$$
对比学习
1# 序列: [x1, x2, x3, x4, x5, x6, x7, x8]
2
3# positive sample
4# x1, x2, x3, x4 => c <=> x5, x6, x7, x8
5
6# negative sample
7# x1, x2, x3, x4 => c <=> xa, xb, xc, xd (同batch中其他的)
迫使模型学习序列间的high level feature,学习这种内部的顺序逻辑关系
互信息公式 - 衡量两个随机变量之间的相互依赖程度 $$ I(x;c)=\sum_{x,c}p(x,c)\log\frac{p(x|c)}{p(x)}. \ I(x;c): x 与 c 的互信息\ p(x,c): x 和 c 同时发生的联合概率分布\ p(x|c): 给定 c 的条件下,x 发生的条件概率分布\ p(x): x 的边缘概率分布 $$ InfoNCE Loss
最小化CPC定义的损失 => 实际上最大化 context c_t 和待预测正样本 X_t 之间的互信息
优化目标:最大化似然概率
正相关
近似计算互信息
Loss
X = {x1, x2, …, xN} N个负样本,从batch中其他数据中采样
E/X 表示似然概率
最大化互信息 => 最小化Loss (互信息下界)
完整InfoNCE-Loss $$ \text{InfoNCELoss} = -\frac{1}{N} \sum_{i=1}^{N} \log \frac{\text{exp}(s(x_i, x_i^+))}{\text{exp}(s(x_i, x_i^+)) + \sum_{j=1}^{K} \text{exp}(s(x_i, x_j^-))} $$
不太了解这个最大化互信息的Loss
DALL·E 2 - 2022.3 OpenAI
Hierarchical Text-Conditional Image Generation with CLIP Latents
层级式图生文
模型架构
描述:
- 虚线上是CLIP架构(文本和图像的联合表示空间),学习图文对的关联信息(图文对关联关系)
- 虚线下是生成框架,prior模型根据Text Embedding生成出CLIP对应的Image Embedding, decoder(diffussion model)根据Image Embedding进行重建
⭐分步训练
训练prior组件
目的:生成CLIP image Embedding
训练decoder
是根据image Embedding生成图片 – 并且这个decoder是多个堆叠,先生成低分辨率,再高清化 - (diffusion model)
简洁表示:
y - 文字
x - 图片
zi - 图片嵌入 (显式生成图像表示可以提高图像多样性,同时将照片真实性和标题相似度的损失降至最低)
diffusion model - NeurIPS 2020
Denoising Diffusion Probabilistic Models
框架:
加噪 + 去噪(还原)
正向过程:
1️⃣ Xt 是 前一张图片加噪生成的,Z1是服从正太分布的噪声
βt是超参数=范围为[0.0001,0.02]递增,则αt 是随时间减少, 表示公式一中原图信息越来越少,噪声越来越重
2️⃣ 递推带入一下
最后可得···
Zt_hat 是一个服从正太分布的随机噪声,at_hat = at*at-1*···*a1, 可由X0直接产生任意时间步的加噪图片
反向去噪过程:
核心基础
1️⃣ 用Xt生成Xt-1 ,按贝叶斯公式转换
2️⃣ q(Xt|Xt-1) == q(Xt|Xt-1, X0), 而q(Xt-1) == q(Xt-1|X0) 任意步加噪图可由原图直接产生
3️⃣ 反解公式7, X0可由Xt进行估计
4️⃣ 带入并整理
··· 因此可根据Xt => Xt-1, 下式为最终的去噪公式 $$ x = \frac{1}{\sqrt{\alpha}} \left( x - \frac{1 - \alpha}{\sqrt{1 - \alpha_{\text{hat}}}} \cdot \text{predicted_noise} \right) + \sqrt{\beta} \cdot \text{noise} $$ β noise 保证多样性
Ɛθ表示预测模型
代码逻辑
训练:
1for i, images in enumerate(pbar):
2 images = images.to(device)
3 t = diffusion.sample_timesteps(images.shape[0]).to(device) # 采样几个时间步进行训练
4 x_t, noise = diffusion.noise_images(images, t) # @ 公式-7
5 predicted_noise = model(x_t, t) # Unet
6 loss = mse(noise, predicted_noise)
7
8 optimizer.zero_grad()
9 loss.backward()
10 optimizer.step()
11
12sampled_images = diffusion.sample(model, n=images.shape[0]) # @ 去噪公式
预测模型
Unet 带时间点嵌入(用余弦-位置嵌入实现的)
1def forward(self, x, t):
2 t = t.unsqueeze(-1).type(torch.float)
3 t = self.pos_encoding(t, self.time_dim) # 嵌入时间步顺序
4
5 x1 = self.inc(x) # cnn
6 x2 = self.down1(x1, t) # pooling
7 x2 = self.sa1(x2) # self attention
8 x3 = self.down2(x2, t)
9 x3 = self.sa2(x3)
10 x4 = self.down3(x3, t)
11 x4 = self.sa3(x4)
12
13 x4 = self.bot1(x4)
14 x4 = self.bot2(x4)
15 x4 = self.bot3(x4)
16
17 x = self.up1(x4, x3, t) # 插值上采样,再拼接skip connect
18 x = self.sa4(x)
19 x = self.up2(x, x2, t)
20 x = self.sa5(x)
21 x = self.up3(x, x1, t)
22 x = self.sa6(x)
23 output = self.outc(x)
24 return output
p(Xt-2|Xt-1, t, y) t是时间步嵌入,y是条件嵌入
最简单的融合方法就是相加
??? 疑惑点 - 反向过程求的t时刻的均值方差用在哪了?
2025/1/14 更新:
// X => X_noise_t 可以一步生成,可以时间步t可以直接生成对应t时间步的噪声图。
// 使用U-net预测时间步t的噪声 使用MSE-Loss进行训练
1# 训练循环
2for epoch in range(num_epochs):
3 for x_0 in dataloader: # x_0 是原始数据
4 # 1. 随机选择一个时间步 t
5 t = torch.randint(0, T, (x_0.size(0),)) # 为每个样本随机选择一个时间步
6
7 # 2. 前向过程:添加噪声
8 epsilon = torch.randn_like(x_0) # 采样噪声
9 alpha_bar_t_t = alpha_bar_t[t].view(-1, 1, 1, 1) # 选择对应时间步的 alpha_bar_t
10 x_t = torch.sqrt(alpha_bar_t_t) * x_0 + torch.sqrt(1 - alpha_bar_t_t) * epsilon # 添加噪声
11
12 # 3. 反向过程:预测噪声
13 predicted_epsilon = model(x_t, t) # 模型预测噪声
14
15 # 4. 计算损失函数
16 loss = F.mse_loss(predicted_epsilon, epsilon) # 均方误差损失
17
18 # 5. 反向传播和优化
19 optimizer.zero_grad()
20 loss.backward()
21 optimizer.step()
// 串行,一步一步去噪
1# 生成过程
2def generate_samples(model, num_samples, T, alpha_bar_t):
3 x_T = torch.randn(num_samples, ...) # 从标准正态分布中采样初始噪声
4 for t in range(T-1, 0, -1): # 从 T-1 到 1
5 # 预测噪声
6 epsilon = model(x_T, t)
7
8 # 计算去噪后的数据 <= 消除噪声
9 alpha_t = alpha_bar_t[t] / alpha_bar_t[t-1]
10 x_T = (x_T - torch.sqrt(1 - alpha_t) * epsilon) / torch.sqrt(alpha_t)
11
12 return x_T
Time-Frequency Consistency - NeurIPS 2022
Self-Supervised Contrastive Pre-Training for Time Series via Time-Frequency Consistency
期望同一示例的基于时间和基于频率的表示在时频空间中靠近在一起
(判别式无监督学习)
pretext task:实例判别 (一对正样本,其余负样本)
框架
时域增强:基于时间特性从 xi 扩充,包括抖动、缩放、时移和邻域分段;
频域增强:频谱特征扰动 xFi 的增强,添加或删除频率分量来扰动频谱 (确保扰动时间序列仍然与原始样本在频域和时域仍相似)
Loss:
余弦相似度:衡量两个向量之间相似性,范围[-1, 1]
// 补充 2025/1/14
样本越相似 => sim(i, j) 越大 => exp(sim) 越大 => exp(sim)/\sum(exp) 越接近于1 => log(·)越接近于0
-log(·) 将图像倒置,样本越不相似 => exp(sim)/\sum(exp) 越接近于0 => loss 越大
COMET - NeurIPS 2023
Contrast Everything A Hierarchical Contrastive Framework for Medical Time-Series
(判别式无监督学习)
- 我们的方法旨在弥合标记数据的有限可用性与医疗时间序列分析中稳健且可概括的模型的需求之间的差距
- 对比表示学习背后的关键思想是通过将相似的数据靠近在一起并将不相似的数据进一步分开来挖掘数据一致性
关键是要利用所有可用的信息;除了样本标签之外,数据集是否还有其他信息?(补充信息)
患者间、患者内进行测试(定义打乱规则)
⭐⭐⭐多级信息
多级对比学习框架
代码分析总结
1X_train.size == [Batch, channels, segment] # segment length 330, sampling_rate = 250Hz
2y_train # 心肌梗塞二分类标签, patient_id, segment_id
细分为样本级别(心跳),故图示Encoder不同级别对比学习可复用
关键,计算不同级别的对比Loss
Patient-Level Loss
1x = [Batch, channels, segment]
2
3out1 = net(x)
4out2 = net(x) # ? 模拟数据增强后的不同视角或版本,以便在对比学习中生成有效的正例和负例
5
6# 根据y_train 病人id,构建mask矩阵
7pid1, pid2 = np.meshgrid(str_pid, str_pid)
8pid_matrix = pid1 + '-' + pid2 # 每项为 id_x - id_y
9# 目标位置 id_x - id_x
10pids_of_interest = np.unique(str_pid + '-' + str_pid) # unique combinations of pids of interest i.e. matching
11bool_matrix_of_interest = np.zeros((len(str_pid), len(str_pid)))
12for pid in pids_of_interest:
13 bool_matrix_of_interest += pid_matrix == pid
14
15# 上三角和下三角目标row,col
16rows1, cols1 = np.where(np.triu(bool_matrix_of_interest, 1)) # upper triangle same patient combs
17rows2, cols2 = np.where(np.tril(bool_matrix_of_interest, -1)) # down triangle same patient combs
18
19out1, out2 => sim_matrix_exp # 余弦相似度矩阵
20
21# @@ 对比学习:不考虑对角线元素的原因主要是因为对角线元素表示的是特征向量与其自身的相似度
22# @@ 我们关注的是如何使具有相同标签的不同特征向量之间更相近,而使不同标签的特征向量之间更疏远
23
24# Loss 分母, 某样本与其他样本相似度之和, @分上三角和下三角
25triu_sum = torch.sum(sim_matrix_exp, 1) # add column
26tril_sum = torch.sum(sim_matrix_exp, 0) # add row
27
28loss_terms = 0 # 取平均
29if len(rows1) > 0:
30 triu_elements = sim_matrix_exp[rows1, cols1] # row and column for upper triangle same patient combinations
31 loss_triu = -torch.mean(torch.log(triu_elements / triu_sum[rows1]))
32 loss += loss_triu # technically need to add 1 more term for symmetry
33 loss_terms += 1
34...
35
36loss = loss/loss_terms
Trial-Level Loss
同上,只不过patient_id => segment_id
❌❌❌Sample-Level Loss & Observation-Level Loss
看不懂源码~ 😎😭
TS2Vec - AAAI 22
TS2Vec: Towards Universal Representation of Time Series
(判别式无监督学习)
现存工作局限:
- 它们都没有以不同尺度的时间序列为特征来捕获尺度不变的信息,而这对于时间序列任务的成功至关重要。多尺度特征可以提供不同级别的语义并提高学习表示的泛化能力
- 粗粒度表示 - 整个时间序列,可能没那么细致
之前工作的问题
正样本对会误判
- 当存在水平偏移时,子系列一致性很容易受到攻击 (左图)
- 当出现异常时,时间一致性可能会引入误报对 (右图)
创新:
- TS2Vec 中的对比目标基于增强上下文视图,即相同子系列在两个增强上下文中的表示应该是一致的 (上下文语境下)
- 层级式对比Loss,由细粒度=>粗粒度,局部到全局 # 学习各种语义级别的任意子系列的上下文表示,灵活且通用的表示。 顶级语义级别的对比使模型能够学习实例(样本)级表示
框架
流程:
- 实例(一段信号),分两个重叠的子序列, [batch, channel, dim_feature]
- 投影,[batch, channel, dim_feature] => [batch, channel, dim_hidden]
- 随机Mask掉部分信号
- CNN-Encoder
⭐⭐⭐ Hierarchical Contrasting Loss
- instance & temporal contrastive loss
*用 -F.log_softmax(x, dim=-1) 实现*
-
z1 = F.max_pool1d(z1.transpose(1, 2), kernel_size=2).transpose(1, 2) z2 = F.max_pool1d(z2.transpose(1, 2), kernel_size=2).transpose(1, 2)
编码特征浓缩,多尺度的Contrast loss
图示Loss过程
子序列是从原始信号中裁剪下来的,并且有重叠部分
同色是相同样本,深浅色表示同一样本重叠的两段
TimesURL - AAAI 2024
TimesURL: Self-Supervised Contrastive Learning for Universal Time Series Representation Learning
代码在TS2Vec上修改
=> 在这里,我们必须提到,重要的时间变化信息,例如趋势和季节,在多次最大池化操作后会丢失,因此顶层对比实际上无法为下游任务捕获足够的实例级信息
=> 掩码重建进行学习实例级信息
(判别式+生成式 混合 无监督学习)
观察
**简单负样本:**大多数时间序列片段可以被视为容易负样本。 这些片段往往表现出与锚点的语义差异,并且仅贡献较小的梯度,因此无法提供有用的区分信息
硬负样本: 硬负样本就是离正样本很近,并且模型很难区别的
正样本-硬负样本-负样本:,这些样本如果让其远离正样本可以大大提高模型性能。 其有效性被大量的简单负样本所掩盖。(现存框架没有特点显示的指出)
由于时间序列中的局部平滑性和马尔可夫特性,大多数负样本很容易不足以捕获时间信息,因为它们从根本上缺乏驱动对比学习所需的学习信号。 作为图 2 中真实示例,对于每个正锚点(红色方块),相应的负样本(灰色标记)包含许多简单的负样本和很少的困难负样本,即许多负片太远,无法造成对比损失。
对比学习的一个关键组成部分是选择适当的增强,这些增强可以施加一些先验来构建可行的正样本,以便编码器可以被训练来学习鲁棒和有区别的表示
频率混合用于通过将通过快速傅里叶变换(FFT)运算计算出的一个训练实例 xi 中的一定比例的频率分量替换为同一批次中的另一个随机训练实例 xk 的相同频率分量来生成新的上下文视图 (保持病理相同)
随机裁剪。 重叠两个子序列 - 随机裁剪是上下文一致性策略的关键步骤。 它可以保持时间序列的重要时间关系和语义一致性
创新点:
- 提出双Universum概念,就是利用Mix-up增强F(x),追加硬负样本。
- 对比学习+自监督掩码重建,联合优化,来捕获段级和实例级信息, 实现通用表示
⭐ 第一类包括预测、异常检测和插补,它们更多地依赖于在分段级别捕获的细粒度信息,因为这些任务需要推断特定的时间戳或子序列。细粒度(局部)
⭐ 第二类包括分类和聚类优先考虑实例级信息(即粗粒度信息),旨在推断整个系列的目标。粗粒度(全局)
实现 : 分段(对比学习,学习片段),整句(掩码重建,学习整体)
框架:
AUG:
频率增强,**x => fft() =mask+fusion=> ifft() => y**,①该篇论文fusion是融合同batch其他信号的某些部分 => 领域创新 (fusion的信号应该和这个信号相同病理,扩张数据分布)
DualConv:
原始信号的两个增强子视图,z1 = Encoder(x1), z1' = Encoder(x1'), => mix-up option => **z1_mix = α × z1 + (1-α) × z1[torch.randperm(z1.shape[0])]**,z1'_mix。
[z1, z1', z1_mix, z1'mix] @ [z1, z1', z1_mix, z1'mix].T => sim => **-F.log_softmax(sim)**
loss: 俩视图对应段为正样本(分子)
负样本在母分,x_mix做负样本增强。
Mixup - 2017 Machine Learning
mixup: BEYOND EMPIRICAL RISK MINIMIZATION
一种简单并且不需要专业领域知识的数据增强
现存问题讨论:
- 过拟合(大模型,直接记忆Train data,走捷径) - overfitting
- 精心设计样本(对抗性例子,人难以察觉,但模型会给出错误的答案) - generalize
👇
ERM(经验风险最小化原则)问题
- 一方面,即使存在强正则化,ERM 也允许大型神经网络记忆(而不是归纳)训练数据
- 另一方面,使用 ERM 训练的神经网络在对训练分布之外的示例进行评估时会极大地改变其预测。
CV: 图像的邻近区域定义为其水平反射、轻微旋转和轻微缩放的集合
=> 数据增强始终可以提高泛化能力, 但该过程依赖于数据集,因此需要使用专家知识 (不同领域增强不一定通用)
数据增强假设邻近的示例共享同一类,并且不会对不同类的示例之间的邻近关系进行建模。(聚类)
=> 邻近风险最小化 (VRM) 原则
⭐=> 从训练样例的邻近分布中提取额外的虚拟样例,以扩大训练分布的支持度
方法:
框架伪代码:
图例:
虚拟数据,让数据边界过渡; 当不在Train数据的分布出现时,降低不确定性。 稍微清晰化边界
YOLO-v1 - CVPR 2016
You Only Look Once: Unified, Real-Time Object Detection
⭐将目标检测视作回归问题 => 预测出来
前向推理
Model:
input: [3, 448, 448] => output: [30, 7, 7]
置信度(confidence): 这个值代表了模型认为预测的边界框内存在对象的概率
框的中心坐标 + 宽高
框中的物体是什么类
非极大值抑制 (最佳:每个类别独立执行非极大值抑制,从而更精确地处理多类别情况)
- 置信度排序:首先将所有的预测边界框按照它们的置信度(confidence scores)进行降序排序。
- 选择最高置信度边界框:从排序后的列表中选择置信度最高的边界框作为参考框(reference box)。
- 计算IOU:计算选中的参考框与列表中其他所有边界框的交并比(IOU)。交并比是两个边界框的交集面积与它们的并集面积的比值。
- 抑制:如果参考框与任何其他边界框的IOU超过预先设定的阈值(通常设置为0.5),那么这些边界框会被认为是多余的,并从列表中删除。
- 重复步骤:从剩余的边界框列表中再次选择置信度最高的边界框,重复上述过程,直到所有的边界框都被处理完毕。
- 最终结果:经过非极大值抑制后,剩余的边界框被认为是对目标位置的最佳预测,它们将被用于最终的目标检测输出。
训练:
λcoord = 5, λnoobj = 0.5, 调整各个部分的重要性 $$ 1_{ij}^{obj}: 表示第ij个格子有对象 \ 1_{ij}^{noobj}: 表示第ij个格子没有对象\ S^{2}: 图片划分格子 \ B: 每个格子预测多少个框 $$ bounding box loss : 中心点 + 框宽高
confidence: 格子是否有对象
classes:格子分类是否正确
Semi-Supervised Hybrid Loss - Machine Learning 2023
Semi-Supervised End-To-End Contrastive Learning For Time Series Classification
1️⃣无标签数据对比学习(增强视图一致性),2️⃣有标签对比学习(相同种类一致性),3️⃣有标签分类监督学习
(判别式无监督学习 + 有监督学习)
框架对比
⭐ End to End
框架
Unlabeled Sample : 使用两个增强视图作为positive pair,与其他sample为negative pair (标准的对比学习)
Labeled Sample:1️⃣ 同类型的sample为positive pair,不同类型的sample为negative pair. 2️⃣过分类头,计算分类Loss
❤️ 混合上述三个Loss,联合优化Encoder
SimCLR - 2020
A Simple Framework for Contrastive Learning of Visual Representations
贡献:
-
数据增强对于对比学习至关重要 (裁剪缩放,翻转,颜色紊乱,旋转, 掩盖, 高斯噪声, 高斯模糊,Sobel 滤波) - 裁剪缩放+颜色紊乱 比较好
-
在经过Resnet编码器后,追加MLP能增强模型性能
-
样本x,增强视图xi和xj(正样本),batch size =N,一共2N的增强视图,对于某个样本x,xi和xj为正样本,和batch中剩余的样本的增强为负样本
(大batchsize, 性能更好, 全局BN)
样本自成一类,来尽可能地让编码器找到图像中最重要的特征
框架
共享参数 shared weight
Loss
上面是正样本对,下面是负样本对 -log_softmax() => 挑选出需要的值
算法
ViLT - 2021
ViLT Vision-and-Language Transformer Without Convolution or Region Supervision
极简结构的图片文多模态融合
速度限制-问题分析
归纳总结:
(a) vision embedding 参数量 > Text Embedding > Modality Interaction # 缺点,视觉嵌入太重(比重太大),并且融合非常简单即点乘算相似度
(b) vision embedding和Text embedding 占比差不多 > Modality Interaction # 模态融合之前,工作太繁杂,而且前抽取特征不好,限制后面融合,并且不重视后面的模态融合操作。
(c) 重视visual Embed和后期的modality interaction,# text 和 vision不均等,重要性不平衡
=> 简单框架,Text词嵌入(bert中的BertEmbeddings加载训练后的权重),vision用patch projection,都很快
⭐ 1. 图像和文本前期嵌入应该有相似均匀的表达能力 2. 这两种模态是否在深层网络中相互作用。
模型框架:
初始化参数-ViT,而不是bert
优化目标(主要):
- Image Text Matching:0.5概率将图片替换为与文本不匹配的图片,预测一致性(二分类问题)
- Masked Language Modeling:预测被遮掩的词
text cls: 预测图文是否一致,二分类
text token set: 全局上下文=>预被掩词
text token set 和 visual token set:进行对齐Loss
BEIT-v3 2022
Image as a Foreign Language: BEIT Pretraining for All Vision and Vision-Language Tasks
统一Vision 和 NLP
⭐ 核心思想是图像可以被建模为一门外语,这样我们就可以对图像、文本和图文对进行统一的掩码“语言”建模。
结果非常好
基础块
共享注意力矩阵(都是一个物体的不同视角),但是最后的FFN各个模态专享
拓展到不同的模态:
任务:
图像字幕任务:采用了特殊的自注意力掩模。 图像标记(即图像块)只能在图像序列内双向相互关注。 标题的标记可以关注图像标记、它们的左侧标题标记以及它们本身。 在微调过程中,我们随机屏蔽一定比例的标题标记。 该模型经过训练,可以根据图像的线索及其左侧标题上下文来恢复这些标记。 我们还屏蔽了特殊的边界标记 [SEP],以帮助模型学习终止生成
视觉问答: 将任务表述为分类问题。 该模型经过训练,可以从训练集中 3129 个最常见的候选答案中预测答案。我们将给定问题和图像的嵌入连接起来,然后将输入嵌入输入多路转换器以联合编码图像-问题对。 最终的池化输出被输入到分类器层来预测答案。
**图像文本检索任务:**是测量图像和文本之间的相似度。 根据检索目标的模态,有两个方向:图像到文本检索和文本到图像检索。 双编码器模型分别对图像和文本进行编码以获得它们的表示。 然后我们计算这些表示的余弦相似度分数。
图像分类: 将该任务制定为图像到文本检索任务。 我们使用类别名称作为文本来构建图像-文本对。 BEIT-3 被训练为双编码器,以找到图像最相关的标签。 在推理过程中,我们首先计算可能的类名的特征嵌入和图像的特征嵌入。 然后计算它们的余弦相似度分数以预测每个图像最可能的标签。
ALBEF - 2021
Align before Fuse: Vision and Language Representation Learning with Momentum Distillation
现存问题:大多数现有方法采用基于变压器的多模态编码器来联合建模-视觉Token(基于区域的图像特征)和文本Token。 由于视觉标记和单词标记未对齐,因此多模态编码器学习图像文本交互具有挑战性。
(1)图像特征和文本符号映射仍然停留在他们自己的空间,使得多模态编码器很难学习建模他们之间的交互;
(2)物体检测器 — 标注费钱,使用费算力 — 在预训练阶段需要标注矩形框,在推理阶段高分辨率图像,如 600*1000,速度较慢;
(3)广泛使用的 image-text 数据集均是从网上搜集的带有严重噪声的数据,现有的预训练目标,如 MLM 可能过拟合到文本数据,降低了模型的泛化性能。
框架:
image encoder: ViT(ImageNet预训练参数) - CLS token
text encoder: Bert(预训练参数) - CLS token
multimodal encoder: Bert(预训练参数) + cross-attention
⭐ **在传入multi-modal encoder前,使用ITC迫使模型进行对齐 ** align before fuse的align
- 对齐图像特征和文本特征,使多模态融合编码器更容易执行跨模态学习
- 改进了单模态编码器,以更好地理解图像和文本的语义
- 它学习一个共同的低维空间来嵌入图像和文本,这使得图像文本匹配目标能够通过我们的对比硬负挖掘找到更多信息样本。
Image-Text Contrastive Loss:
正样本对:配对的Image-Text
负样本对:Queue存储着的样本表示
Image => 匹配Text-Queue(Momentum)
Text => 匹配Image-Queue(Momentum)
(代码中利用了Momentum Distillation …)
Image-Text Matching:
有了multi-modal encoder输出的 embed token (正确样本的表征) => 即喂入Multi-modal encoder的 text embed = (positive), Image embed = (positive), 拿融合的CLS作为最终表征,过MLP => 二分类预测是否匹配;这部分Targets=(1, 1, …, 1)
从同batch中,按相似性大小随机挑选一个(hard)负样本,
然后,text embed = (positive, …, negetive, …) , Image embed = (negetive, …, positive)
multi-modal encoder => CLS => MLP => two probability
Targets = (0, 0, …, 0)
// 重新梳理如下:
1# 图像i-文本j => 多模态编码器 => 是否匹配;
2图像 1-文本 1 : 匹配对
3图像 2-文本 2 : 匹配对
4图像 1-文本 2 : 不匹配 // 这里使用余弦相似度选取最困难的样本
5图像 2-文本 1 : 不匹配 // 这里使用余弦相似度选取最困难的样本
Masked Language Modeling:
屏蔽掉一些词,通过从图片模态信息中预测掉被屏蔽的词(多分类Loss)
这里也借助了图像的信息去更好的恢复被mask掉的单词
【这里只对匹配的对计算 掩码Loss】
目的:缓解noisy web data的不足,真正的label不一定有momentum的好
真实label不一定比momentum model给出的predict label好,=> 使用KL散度进行约束 一致性
最大化互信息视角解释:
在自监督学习中,a 和 b 是同一图像的两个增强。 在视觉语言表示学习中,我们将 a 和 b 视为捕获其语义的图像文本对的不同变体。 我们的目标是学习对观点变化不变的表征。
最小化Loss => 最大化互信息的下限(最大化了图像-文本对的**不同“视图”**之间的互信息(MI)的下限)
InfoNCE Loss
Image-Text Contrastive Loss
最大化Text和Image中的互信息, ITC 将两个单独的模态(即 I 和 T)视为图像-文本对的两个视图
MLM:
MLM 将图像-文本对的两个视图视为:(1) 随机选择的单词标记,以及 (2) 图像 + 带有该单词屏蔽的上下文文本。
Instance discrimination - 2018
Unsupervised Feature Learning via Non-Parametric Instance Discrimination
首次提出个体判别任务!
观察:
在监督学习中。在预测’花豹’时,预测概率除了’花豹’,剩余预测得分比较高的是’美洲虎’、‘猎豹’; 最不相似的是’救生艇’、‘购物车’、‘书柜’;
最高响应的类都是视觉相关的
⭐ 并不是语义标签,而是数据本身的明显相似性使某些类比其他类更接近;
❗❗❗ 个体判别:将类监督发挥到了极致,并学习了区分各个实例的特征表示。
这些观察结果表明,典型的判别学习方法可以自动发现语义类别之间的明显相似性,而无需明确指导这样做。
我们能否通过纯粹的判别学习来学习反映实例之间明显相似性的有意义的度量? 图像本身就是独特的,并且每个图像都可能与同一语义类别中的其他图像显着不同。如果我们学会在没有任何语义类别概念的情况下区分各个实例,我们最终可能会得到一个捕获实例之间明显相似性的表示,就像类明智的监督学习如何仍然保留类之间的明显相似性一样。
目标:
在没有监督的情况下学习嵌入函数 v = fθ(x)。 fθ 是一个具有参数 θ 的深度神经网络,将图像 x 映射到特征 v。这种嵌入将在图像空间上产生一个度量,对于实例 x 和 y, dθ(x, y) = |fθ(x) − fθ(y)|。 良好的嵌入应该将视觉上相似的图像映射得彼此更接近。 我们新颖的无监督特征学习方法是实例级区分。 我们将每个图像实例视为其自己的不同类,并训练分类器来区分各个实例类。
方法:
用一个memory bank存储4096个样本embed feature(128-dimention) 随着网络更新, 目的是让特征在嵌入空间中远离(每一个样本都是一个类),学习那种有监督时类和类之间相似聚集的现象。
BYOL - 2020/6
Bootstrap Your Own Latent A New Approach to Self-Supervised Learning
1无监督学习: {
2 判别式:从增强视图的表示中,他们学会区分同一图像的另一个增强视图的表示和不同图像的增强视图的表示 => 这种判别方法通常需要将增强视图的每个表示与许多反例进行比较。
3 生成式:通过预测同一图像的不同视图(例如,不同的随机裁剪)来学习表示 => 图像的增强视图的表示应该能够预测同一图像的另一个增强视图的表示。
4}
方法:
在线网络θ + 目标网络γ(提供回归目标,γ = α×γ + (1-α)×θ ,指数移动平均 )
yθ是目标编码器,其余的训练好后丢掉
⭐一张图片的两个增强表示的相同的语义 => 在高维的嵌入表示中,应该可以预测对方(相近)
1yθ:Encoder
2zθ:Projection head
3qθ:Prediction head
Loss:
$$
注意图像增强t(x)和t^{}x会对等的传给online\ net 和 target\ net\\ Loss: 1/2 × ( || q_{θ}(z_{θ}) - z^{}{ξ}||^{2} + || q{θ}(z_{θ}) - z^{`}_{ξ}||^{2} )
$$
Train:
$$
θ:online\ net\ parameters\
ξ:target\ net\ parameters\
θ <- optimizer(θ),\ \ \ ξ <- αξ + (1-α)θ
$$
DINO - 2021
Emerging Properties in Self-Supervised Vision Transformers
ViT最后的CLS注意力图示⭐⭐⭐
探讨:质疑自监督学习是否为 Vision Transformer (ViT) 提供了比卷积网络 (convnets) 更突出的新属性?
框架:(借鉴BYOL)
教师是在训练过程中动态构建的。知识蒸馏就不再被用作自监督预训练的后处理步骤,而是直接作为自监督目标。
其中学生和教师具有相同的架构并在训练期间使用蒸馏。
教师在我们工作中用学生的动量平均值进行更新。
增强策略:
1. 多裁剪策略构建图像的不同扭曲视图或裁剪。 更准确地说,根据给定的图像,我们生成一组 V 的不同视图。 该集合包含两个全局视图 xg 1 和 xg 2 以及几个分辨率较小的局部视图。
1. 所有的裁剪都通过学生传递,而只有全局观点通过老师传递,因此鼓励“局部到全局”的对应。
伪代码:
防止模型坍塌:
1. *对动量教师输出进行居中和锐化,以避免模型崩溃。*
2. **居中(Centering)**:对动量教师的输出进行居中操作是为了减少批次之间的偏差,增加输出的稳定性。具体做法是从每个输出中减去其均值,确保输出围绕零分布,这有助于避免网络输出在特征空间内偏向某一方向,从而降低了模型坍塌的风险。
3. **锐化(Sharpening)**:锐化是通过增加输出分布的峰值来实现的,目的是使模型的输出更加区分明显,即使不同类别之间的区别更加清晰。这通常通过提高输出概率分布的熵来实现,比如可以采用温度调整(temperature scaling)等方法来调整概率分布,使得主要的概率值更加突出,而其他的概率值则相对降低。
图示:
不同颜色是不同的注意力头
无监督注意力更能学到本质!
SimSiam - CVPR 2021
Exploring Simple Siamese Representation Learning
简单设计的Siamese(孪生)网络。 我们的极简主义方法的竞争力表明
1️⃣ “没有动量编码器的 BYOL”
2️⃣ “没有负样本的 SimCLR“ + stop-grad(⭐这个非常关键, 这个对防止模型坍塌很关键)
方法:
一幅图像的两个增强视图由同一编码器网络 f(主干网络加投影 MLP)处理。 然后在一侧应用预测 MLP-h,在另一侧应用停止梯度操作。 该模型最大化了双方之间的相似性。 它既不使用负对也不使用动量编码器。
伪代码:
消融
Loss:
负的余弦相似度 和 交叉熵
相似度:
交叉熵:
BatchNorm的影响:
BatchSize的影响:
预测头的影响:
Loss的对称性:
sym对称;asym非对称;asym. 2×(每个图像采样两对来粗略地补偿对称性)
Segment Anything
即时分割
模型组件
模型框架:
prompt encoder:
- Sparse prompts:
- point: point => 256 dimensional vectorial embedding. 这个使用index去索引位置嵌入像Swin-T, foreground or backgroud embedding(自学习). to add together.
- box: 左上角位置编码 + 左上角的学习嵌入;左上角位置编码+“右下角”的学习嵌入
- text: clip的text encoder.
- dense prompts:
- mask: CNN => 256 特征向量。有则加mask,没有就加可学习的表示无mask的学习嵌入
mask decoder:
KNN(K-Nearest Neighbors)
K-近邻算法
核心思想:相似的样本具有相似的输出。
=> KNN通过计算输入样本与训练数据集中所有样本的距离,找到距离最近的K个样本,然后根据这些样本的类别来决定输入样本的类别
主要步骤:
-
选择K值:选择一个正整数K,代表你要比较的邻居数量。
-
计算距离:对每个待分类样本,计算它与训练数据集中所有样本的距离。常用的距离度量有欧氏距离、曼哈顿距离和余弦相似度等。
- $$ \textbf{欧氏距离}: d(x, x_i) = \sqrt{\sum_{j=1}^{m}(x_j-x_{ij})^2} $$
-
选择最近的K个邻居:根据计算得到的距离,从训练数据集中选择距离待分类样本最近的K个样本
-
投票或加权:在分类任务中,K个邻居中最多的类别即为待分类样本的预测类别。在回归任务中,可以对K个邻居的数值进行平均或者加权平均。
-
输出结果:输出投票或加权后的结果作为待分类样本的预测结果。
PatchTST - ICLR 2023
-
Patchify .
- 有监督 => 可以重叠
- 自监督 => 不可以重叠,避免网络可以从重叠区域走捷径学习
-
多变量独立:
-
每个时间序列将有自己的潜在表示,通过共享权重机制交叉学习 ???
共享Encoder权重,不同通道使用相同的模型参数。这种方法允许模型在不同的任务之间共享知识
-
Overview
1x = [batch, channel, length]
2x = [batch, channel, num_token, len_token]
3x = [batch*channel, num_sample, dim_hidden]
4
5=> Transformer Encoder but residual attn #
6
7=> Linear head =>
CrossFormer - ICLR 2023
TRANSFORMER UTILIZING CROSSDIMENSION DEPENDENCY FOR MULTIVARIATE TIME SERIES FORECASTING
创新点:
- 显示建模时间依赖关系 + 通道依赖关系
- 两阶段注意力 (时间:MHSA,通道:Router MHSA)
嵌入方式 and 依据:
自注意力呈现小局部一致性,一坨而不是一个。
- 保持通道独立 ✔️
- 注意力优化 ✔️
TwoStageAttention
1# Step 1. Time Dependency
2x = [batch, channel, length]
3x = [batch, channel, num_patch, dim_patch] # <= DSW (Dimension-Segment-Wise)
4x = [batch*channel, num_patch, dim_patch]
5y = TransformerEncoer(x, x, x) # <= capture time dependency
6
7# Step 2. Channel Dependency
8y = [batch, channel, num_patch, dim_patch]
9y = [batch*num_patch, channel, dim_patch]
10router = [1, num_router, dim_patch] # <= router
11router => repeat => [*, num_router, dim_patch]
12z = TransformerEncoder(router, y, y) # <= capture channel dependency
13z = TransformerEncoder(y, router, router)
14
15# save per stage output
16=> Unet Decoder => to predict
ECG与多变量的异同:
- 相似点
- 不同通道贡献不同 => DSW-patch, 能够更加细粒度编码局部波形 == 多变量(通道)
- patch化的成功!!!
- 不同点
- 由于是对心脏电活动的同一时间不同角度的观察 => 病理位置相同 =>是否能够通过共享策略 降低计算成本🤔❓
Informer - AAAI 2021 Best
– TopK-Q
观察:(Q&K 是等价的)
注意力呈现长尾分布:
Query分为活跃于惰性Token
衡量指标:
注意力优化:
1Q, K, V
2# probe
3K = [batch, num_head, len_token, dim_head]
4K_sample = [batch, num_head, random_len, dim_head]
5Q_K_sample = [batch, num_head, len_token, random_len]
6M = Q_K_sample.max(-1)[0] - torch.div(Q_K_sample.sum(-1), L_K) # 衡量指标
7M_top = M.topk(n_top, sorted=False)[1]
8
9Q_reduce = Q[:, :, M_top, :]
10attn_active = softmax(torch.matmul(Q_reduce, K.transpose(-2, -1))*scale)
11
12contex = V.sum(-2).expand() => [batch, num_head, len_token, dim_head] # 均匀分布的就直接取V的均值
13contex[:, :, M_top, :] = attn_active@V
结构优化:
1# Encoder:
2for num_layer ...:
3 x = attn(x)
4 x = conv_layer(x) # <- maxpool(act(norm(conv())))
5return enc_out
1# Decoder:
2cross = enc_out
3x = # 预测引导
4for num_layer ...:
5 x = layer(x, cross, x_mask=x_mask, cross_mask=cross_mask) # Note:Masked MHSA-ProbeAttn
框架逻辑
1Class Exp_Basic(Object):
2 def __init__():
3 def _build_model():
4 def _acquire_device():
5 def _get_data():
6 def train():
7 def vali():
8 def test(self):
9
10Class Exp_Model(Exp_Basic):
11 def _select_optimizer():
12 def _select_criterion():
13 def _process_on_batch():
1# data_loader.py
2Class Dataset_XXX(Dataset):
3 def __init__():
4 def __read_data__(self):
5 def __getitem__(self, index):
6 def __len__(self):
1# main.py
2
3parser = argparse.ArgumentParser(description='[Model] Task')
4...
5args = parser.parse_args()
6setting = ...args
7
8exp = Exp_Model(args)
9exp.train(setting)
10exp.test(setting)
Adaptive Token Dictionary - CVPR2024
Transcending the Limit of Local Window: Advanced Super-Resolution Transformer with Adaptive Token Dictionary
扩展局部窗口的限制
- window-based self-attention
- token dictionary cross-attention => Attention(Q(XW),K(TW), V(TW))
- 基于2的Attn,将token map排序分group(类),进行group内部的Attention
Architecture
Poly Kernel Inception - CVPR 2024
Poly Kernel Inception Network for Remote Sensing Detection
遥感图像中的目标检测面临着多种挑战,包括目标尺度变化大、测距环境多样等。现有的方法试图通过大核卷积或扩张卷积来扩展脊柱的空间感受野来解决这些挑战。然而,前者通常会引入相当大的背景噪声,而后者则有生成过度稀疏的特征表示的风险。本文提出了一种多核初始化网络(PKINet)来解决上述问题。PKINet采用无膨胀的多尺度卷积核来提取不同尺度的对象特征并捕获局部上下文。此外,一个上下文锚注意(CAA)模块并行引入捕获远程上下文信息。
- 不同尺度-局部上下文
- 并行引入捕获远程上下文信息
1# 十字架型汇聚 => 近似标准的DWConvKxK => 降低参数量
2agg = Conv1x1(AvgPool(X))
3agg = Conv1x1(DWConvKx1(DWConv1xK(agg)))
4attn = Sigmoid(agg)
DANet - CVPR 2019
Dual Attention Network for Scene Segmentation
At the end of the model, we use the dual attention mechanism to explicitly capture position and channel dependencies.
1class PAM_Module(Module):
2 """ Position attention module"""
3 #Ref from SAGAN
4 def __init__(self, in_dim):
5 super(PAM_Module, self).__init__()
6 self.chanel_in = in_dim
7
8 self.query_conv = Conv2d(in_channels=in_dim, out_channels=in_dim//8, kernel_size=1)
9 self.key_conv = Conv2d(in_channels=in_dim, out_channels=in_dim//8, kernel_size=1)
10 self.value_conv = Conv2d(in_channels=in_dim, out_channels=in_dim, kernel_size=1)
11 self.gamma = Parameter(torch.zeros(1))
12
13 self.softmax = Softmax(dim=-1)
14 def forward(self, x):
15 """
16 inputs :
17 x : input feature maps( B X C X H X W)
18 returns :
19 out : attention value + input feature
20 attention: B X (HxW) X (HxW)
21 """
22 m_batchsize, C, height, width = x.size()
23 proj_query = self.query_conv(x).view(m_batchsize, -1, width*height).permute(0, 2, 1)
24 proj_key = self.key_conv(x).view(m_batchsize, -1, width*height)
25 energy = torch.bmm(proj_query, proj_key)
26 attention = self.softmax(energy)
27 proj_value = self.value_conv(x).view(m_batchsize, -1, width*height)
28
29 out = torch.bmm(proj_value, attention.permute(0, 2, 1))
30 out = out.view(m_batchsize, C, height, width)
31
32 out = self.gamma*out + x
33 return out
34
35
36class CAM_Module(Module):
37 """ Channel attention module"""
38 def __init__(self, in_dim):
39 super(CAM_Module, self).__init__()
40 self.chanel_in = in_dim
41
42
43 self.gamma = Parameter(torch.zeros(1))
44 self.softmax = Softmax(dim=-1)
45 def forward(self,x):
46 """
47 inputs :
48 x : input feature maps( B X C X H X W)
49 returns :
50 out : attention value + input feature
51 attention: B X C X C
52 """
53 m_batchsize, C, height, width = x.size()
54 proj_query = x.view(m_batchsize, C, -1)
55 proj_key = x.view(m_batchsize, C, -1).permute(0, 2, 1)
56 energy = torch.bmm(proj_query, proj_key)
57 energy_new = torch.max(energy, -1, keepdim=True)[0].expand_as(energy)-energy
58 attention = self.softmax(energy_new)
59 proj_value = x.view(m_batchsize, C, -1)
60
61 out = torch.bmm(attention, proj_value)
62 out = out.view(m_batchsize, C, height, width)
63
64 out = self.gamma*out + x
65 return out
MixNet
MixConv: Mixed Depthwise Convolutional Kernels
convulution => capture local pattern
- early stages: edges
- later stages: objects⭐
这项研究表明了单个内核大小的局限性:我们既需要大内核来捕获高分辨率模式,也需要小内核来捕获低分辨率模式,以获得更好的模型精度和效率
在单一机制下实现多种效果,进行增强
Multimodal Learning
Multimodal Learning With Transformers: A Survey
融合策略
Dual Aggregation Transformer
Dual Aggregation Transformer for Image Super-Resolution
Motivation: 现有方法利用自我注意沿着不同的维度,空间或通道,并取得了令人印象深刻的性能。这启发我们将Transformer中的两个维度结合起来,以获得更强大的表示能力。
Dual Vision Transformer
研究全局语义和更精细的像素级特征之间的依赖关系 => pixel-level token & semantic token
分解和集成的全局语义和本地功能
Fish-Speech Tech-report
Text-to-Speech End2End Model
两阶段训练策略:
Stage 1:
Audio:Mel Spectrogram => 【Encoder】 => Embedding => Quantize Tokens => 【⭐Decoder⭐】=> Audio
**⭐重构目标⭐**
Stage 2:
Text:Quantize Tokens => 【✨AR Model✨】=> Quantize Tokens
⭐**Text:Audio一致性 + 自回归预测Next**⭐
Inference:
Text:Prompt-Tokens => 【✨AR Model✨】=> Quantize Tokens => 【⭐Decoder⭐】=> Audio
Vector Quantize Tech:
Example:
1有一组连续的温度数据(如 20.3°C, 21.7°C, 22.5°C, 19.8°C),你想将其离散化为几个类别:
21.低温: 15°C - 20°C
32.中温: 20°C - 25°C
43.高温: 25°C - 30°C
5=>
620.3°C → 中温
721.7°C → 中温
822.5°C → 中温
919.8°C → 低温
10
11假设编码本有 512 个向量 Shape:[512, dim]
12Encoder得到的Embedding Shape:[T, dim]
13对于 Encoder 输出的每个时间步的特征向量,VQ 会找到编码本中与之最接近的向量,并用其索引表示。
14最终输出是一个离散的索引序列,例如 [42, 123, 87, ...],每个索引对应编码本中的一个向量。
15
16编码本随机初始化,在训练过程中,编码本会通过梯度下降和优化算法(如 Adam)不断更新:
17最近邻搜索 => 量化误差计算 => 梯度更新,BP
18编码本的作用 => 降维与压缩 + 离散化表示 + 提升生成质量(通过离散化减少生成过程中的模糊性,提升生成语音的自然度s)
Blip
- Image-2-Text 任务之一
Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation Architecture
相同颜色共享参数
Stage 1:
Image => 【Image Encoder:ViT】 => image Embedding
Text => 【Text Encoder:Bert】 => text Embedding
目标:图文一致性, 训练Encoder
Stage 2:
Image => 【Image Encoder:ViT:Freeze🥶】 => image Embedding
Text => 【Text Encoder:Bert:Freeze🥶 + Cross-Attention:image Embedding🥵】 => Linear:2class
目标:图文是否匹配-2分类, 训练Cross-Attention部分
Stage 3:
Image => 【Image Encoder:ViT:Freeze🥶】 => image Embedding
Text => 【Text Decoder:GPT🥵 + Cross-Attention:image Embedding:Freeze🥶】 => Linear:multi-class
目标:Image Embedding + text 自回归预测Next
Inference
Image => 【⭐Image Encoder⭐】 => image Embedding
Prompt-Text => 【⭐Text Decoder:GPT⭐ + Cross-Attention:image Embedding:⭐】 => Linear:multi-class => Next-Token
实现Image => Text
BEVFormer
BEVFormer: Learning Bird’s-Eye-View Representation from Multi-Camera Images via Spatiotemporal Transformers
网络架构信息流思路:
具体:
- 一组可学习的BEV Queries,二维网格,模拟鸟瞰图;
- Spatial Cross Attention,每个视图经过backone提取,拿其中多个层级的输出,拼接为多尺度特征(多个层的特征图,校准通道)。然后每个位置的q,只查询对应几个视图的周边几个k;
- Temporal Attention,t时刻的BEV中的q,查询t-1时刻,相应位置周边的几个k。 这里的t-1时刻的BEV特征,需要通过一个角度还是啥校准空间对齐;
Deformable DETR
architecture figure:
Attn figure:
1# 伪代码 - 单尺度的
2import torch
3import torch.nn as nn
4import torch.nn.functional as F
5
6class DeformableAttention(nn.Module):
7 def __init__(self, embed_dim, num_heads, num_points):
8 super().__init__()
9 self.embed_dim = embed_dim
10 self.num_heads = num_heads
11 self.num_points = num_points
12
13 # 用于预测采样偏移的线性层
14 self.offset_proj = nn.Linear(embed_dim, num_heads * num_points * 2)
15
16 # 用于计算注意力权重的线性层
17 self.attn_proj = nn.Linear(embed_dim, num_heads * num_points)
18
19 # 输出投影层
20 self.out_proj = nn.Linear(embed_dim, embed_dim)
21
22 # reference_points, 每个采样点初始,共用同一个reference_point,靠offset进行局部位置偏移
23 def forward(self, query, reference_points, value):
24 B, N, C = query.shape
25 H, W = value.shape[-2:]
26
27 # 预测采样偏移
28 offsets = self.offset_proj(query).view(B, N, self.num_heads, self.num_points, 2)
29
30 # 生成采样点
31 sampling_points = reference_points.unsqueeze(2) + offsets
32
33 # 双线性插值采样特征值
34 sampled_value = F.grid_sample(
35 value,
36 sampling_points.view(B, -1, H, W, 2),
37 mode='bilinear',
38 align_corners=True
39 ).view(B, N, self.num_heads, self.num_points, C // self.num_heads)
40
41 # 计算注意力权重
42 attn_weights = self.attn_proj(query).view(B, N, self.num_heads, self.num_points)
43 attn_weights = F.softmax(attn_weights, dim=-1)
44
45 # 加权求和
46 output = (sampled_value * attn_weights.unsqueeze(-1)).sum(dim=3)
47 output = output.view(B, N, C)
48
49 # 输出投影
50 output = self.out_proj(output)
51
52 return output
位置编码
绝对位置编码
1patch_embedding: [batch, num_token, dim_token]
2pos_embedding: [batch, num_token, info_pos]
3token = patch_embedding + pos_embedding
4# 1. pos_embedding可为一组可以学习的位置向量
5# 2. Sin\Cos方式
二进制下的位置编码
Sin\Cos方式(浮点下连续的编码):
公式:
例如:
相对位置编码
Swin-Transformer中的
1Attention_score = Q@K.T + B
2B: pos_embedding
1 生成相对位置索引
2 定义相对位置编码表
3 将相对位置偏置加到注意力分数上

隐式位置编码(CV)
1x = DWConv(X) + X
Rope 旋转位置编码
$$ \theta_m = m\cdot \theta_0, \theta_n = n\cdot \theta_0\ q’_m = R(\theta_m) \cdot q_m, \ \ k’n = R(\theta_n) \cdot k_n \ attn_score_m^n = q’_m \cdot k’_n = q_m\cdot k_n\cdot R(\theta_m-\theta_n)\ 根据位置 => 角度差 => 嵌入相对位置信息 $$
其中,位置q与k的相对位置信息通过 以下嵌入: $$ Why \ \ R(\theta_1) \cdot R(\theta_2) = R(\theta_1 + \theta_2) \ \ ? $$ 我们可以通过矩阵乘法来验证这一点。假设有两个旋转矩阵:
$$ R(\theta_1) = \begin{pmatrix} \cos(\theta_1) & -\sin(\theta_1) \ \sin(\theta_1) & \cos(\theta_1) \end{pmatrix}, \quad R(\theta_2) = \begin{pmatrix} \cos(\theta_2) & -\sin(\theta_2) \ \sin(\theta_2) & \cos(\theta_2) \end{pmatrix} $$
它们的乘积为:
$$ R(\theta_1) \cdot R(\theta_2) = \begin{pmatrix} \cos(\theta_1)\cos(\theta_2) - \sin(\theta_1)\sin(\theta_2) & -\cos(\theta_1)\sin(\theta_2) - \sin(\theta_1)\cos(\theta_2) \ \sin(\theta_1)\cos(\theta_2) + \cos(\theta_1)\sin(\theta_2) & -\sin(\theta_1)\sin(\theta_2) + \cos(\theta_1)\cos(\theta_2) \end{pmatrix} $$
利用三角函数的加法公式:
$$ \cos(\theta_1 + \theta_2) = \cos(\theta_1)\cos(\theta_2) - \sin(\theta_1)\sin(\theta_2) $$
$$ \sin(\theta_1 + \theta_2) = \sin(\theta_1)\cos(\theta_2) + \cos(\theta_1)\sin(\theta_2) $$
因此,乘积矩阵可以简化为:
$$ R(\theta_1) \cdot R(\theta_2) = \begin{pmatrix} \cos(\theta_1 + \theta_2) & -\sin(\theta_1 + \theta_2) \ \sin(\theta_1 + \theta_2) & \cos(\theta_1 + \theta_2) \end{pmatrix} = R(\theta_1 + \theta_2) $$
DeepSeek-v3

DeepSeek-MoE

router score 生成:相当于每个路由专家维护自己的向量表示;然后输入与输入x计算点击相似度,softmax生成百分比;
[batchnum_token, dim_token] => [batchnum_token, num_expert] 作为融合时的权重
1# 1. Gate => router score
2scores = linear(x) # [batch*num_token, dim_token] => [batch*num_token, num_expert]
3scores = scores.softmax(dim=-1)
4
5original_scores = scores
6indices = torch.topk(scores, self.topk, dim=-1)[1] # Top索引
7weights = original_scores.gather(1, indices) # 分数权重
8
9counts = torch.bincount(indices.flatten(), minlength=self.n_routed_experts).tolist() # 计数, 统计每个专家被引用的次数
10
11# 专家路由
12for i in range(self.experts_start_idx, self.experts_end_idx):
13 if counts[i] == 0:
14 continue
15 expert = self.experts[i]
16 idx, top = torch.where(indices == i)
17 y[idx] += expert(x[idx]) * weights[idx, top, None] # router expert
18z = self.shared_experts(x) # share expert
19return (y + z).view(shape) # 联合
router-score使用linear生成,可以理解为每个expert有自己的向量表示
score = WX => 输入向量跟expert计算点积相似度,进行信息汇聚
Multi-Head Latent Attention (MLA)
一部分使用Lora思路计算高效但表示受限,另一部分则使用正常
q分为:[低秩q:位置q]
k分为:[低秩kv:位置k]
v:低秩kv

1bsz, seqlen, _ = x.size()
2end_pos = start_pos + seqlen
3
4# query投影:分为无位置部分 和 带位置的部分
5q = self.wq(x)
6q = q.view(bsz, seqlen, self.n_local_heads, self.qk_head_dim)
7q_nope, q_pe = torch.split(q, [self.qk_nope_head_dim, self.qk_rope_head_dim], dim=-1)
8q_pe = apply_rotary_emb(q_pe, freqs_cis)
9
10# kv投影:分为低秩kv联合部分 和 带位置的k部分
11kv = self.wkv_a(x)
12kv, k_pe = torch.split(kv, [self.kv_lora_rank, self.qk_rope_head_dim], dim=-1)
13k_pe = apply_rotary_emb(k_pe.unsqueeze(2), freqs_cis)
14
15# q无位置部分投影到low-rank低秩空间
16wkv_b = self.wkv_b.weight
17wkv_b = wkv_b.view(self.n_local_heads, -1, self.kv_lora_rank)
18q_nope = torch.einsum("bshd,hdc->bshc", q_nope, wkv_b[:, :self.qk_nope_head_dim])
19
20# 缓存低秩kv联合部分 和 带位置的k部分
21self.kv_cache[:bsz, start_pos:end_pos] = kv
22self.pe_cache[:bsz, start_pos:end_pos] = k_pe.squeeze(2)
23
24# (低秩q矩阵 乘 低秩kv联合部分) + (带位置的q部分 乘 带位置的k部分)
25scores = (torch.einsum("bshc,btc->bsht", q_nope, self.kv_cache[:bsz, :end_pos]) +
26 torch.einsum("bshr,btr->bsht", q_pe, self.pe_cache[:bsz, :end_pos])) * self.softmax_scale
27
28if mask is not None:
29 scores += mask.unsqueeze(1) # Decoder核心,mask-score
30scores = scores.softmax(dim=-1, dtype=torch.float32).type_as(x)
31
32# score 矩阵乘 低秩kv联合部分 (attn@Value)
33x = torch.einsum("bsht,btc->bshc", scores, self.kv_cache[:bsz, :end_pos]) # 完整的kv
34x = torch.einsum("bshc,hdc->bshd", x, wkv_b[:, -self.v_head_dim:]) # Lora-升维
35x = self.wo(x.flatten(2)) # 投影
36return x
LoRA
LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS
overview

思路:(添加额外的参数进行微调 => 训练结束后再Fusion)

大大节省参数:
1000x1000的矩阵 => 1000,000 参数
1000x10 @ 10x1000 => 20,000参数
节约50倍参数量
(进行近似操作)
llama3
overview

⭐adding multi-modal capabilities

Image => Image Encoder => image embedding
Text => Text Encoder + Cross-Attn(Image embedding) => enhanced text embedding
Speech => Speech Encoder => Speech Embedding 直接与Text Embeddings前期融合(拼接?)
GQA (Grouped query attention):
========> Head
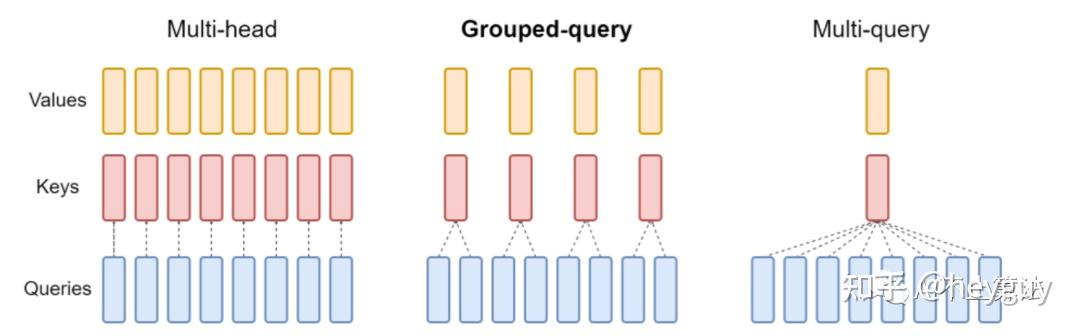
图示中,两个Head中,独立投影生成Queries,但共享一组Key和Value – 减少模型参数(减少投影使用的Linear层)
Training:
Step 1: pre-training. Next Token Predict [Good Knowledge]
Step 2: Post Training => [DPO|direction performance optimizition OR RLHF|Reinforcement Learning from Human Feedback]
$$
y_w:优选项; \ \ y_l:次优项;\
P(y_w > y_l|x) = \frac{e^{r(x,y_w)}}{e^{r(x,y_w)}+e^{r(x,y_l)}} = \frac{1}{1+e^{r(x,y_l)-r(x,y_w)}} \
= σ(r(x,y_w)-r(x,y_l)), σ=Sigmoid(\cdot)\
Max Reward: \frac{1}{num_sample}\cdot-log\prod_{(x,y_w,y_l \in D)}{σ(r(x,y_w)-r(x,y_l))}
$$
优化目标:
前半:最大化偏好项
后半:保持相似性(别偏移太狠,别只顾着回答Train的数据,其他不管了)
Step 3: multi-modal encoder pre-training:
-
image encoder(ViT-H) => text-image pairs representation Alignment [CLIP], 先在224x224的图片上进行预训练,再微调对齐图文一致性
-
speech encoder(Conformer) => [MAE] method. masks out parts of the speech inputs and tries to reconstruct the masked out parts
=> 性能更好的image and speech Encoder
Step 4:
-
Vision adapter training:
每4层之后添加Cross-Attention[训练这部分],引入image-token给core model(llama3)
-
Speech adapter training
encoder: Conformer => [1/2FFN=>MSA=>ConvFFN=>1/2FFN]. 完形填空pre-training
adapter: [Conv-layer => Transformer-layer => Linear => speech token] [训练这部分]
直接作为外语单词嵌入 给 LLM(llama3)的输入。更好的使用core model的能力