图示
卷积注意力
自注意力
学习
Norm
Loss
Cross Entropy
$$
Loss = -\sum_{i}^{C}y_ilog(p(x_{i})), where \ y_i\ is label,p(x_i)\ is\ predict.
$$
BCE Loss
$$ Loss = −\sum_{i}^{c}(y_ilog(p(x_i)+(1−y_i)log(1−p(x_i)) \ where \ y_i \in [0, 1] \
pos_partition = -log(p(x_i))\ neg_partition = -log(1-p(x_i)) $$
Focal Loss
$$ Loss = -α_t(1-p_t)^γlog(p_t)\
# Multi-Label:\ 1.\ pos_loss = α(1-p(x_i))^γ\ \ -log(p_t)\ 2.\ neg_loss = (1-α)p(x_i)^γ\ \ -log(1-p_t) $$
论文
Mlp-mixer - NIPS 2021
title: Mlp-mixer: An all-mlp architecture for vision
⭐ channel-mixing MLPs and token-mixing MLPs.
① 融合Patches间的特征信息
② 融合Patches内的特征信息
❌ 易过拟合
**Transformer ** - NIPS 2017
Transformer Encoder
Multi-Head Self Attention
⭐每段用不一样的α权重 – 分段融合Token间信息
多组注意力权重α
Token分段,并行计算每段的权重α,多头注意力允许模型共同关注来自不同位置的不同表示子空间的信息。
⭐⭐⭐ 并行多个头,增强表示能力,融合不同子空间(低纬空间)
Token间信息融合,比例是相似度权重
Feed-Forward Networks
卷积
深度可分离卷积计算成本比标准卷积小 8 到 9 倍,而精度仅略有降低 - MobileNetV2
✨使用共享内核在局部区域内进行信息交互
标准卷积
输入特征图和模板卷积核
输出像素 - 融合局部空间通道信息
瓶颈结构 - Resnet
减少参数数量
逐点卷积降维 -> 标准卷积 -> 逐点卷积升维
残差连接
压缩 - 卷积 - 扩张
深度可分离卷积
倒残差结构 - MobileNet
扩充通道的原因,是为了能够提取到更多的信息
ReLU 激活函数可能会崩溃掉某些通道信息。然而,如果我们有很多通道,那么信息可能仍然保留在其他通道中。
逐点卷积升维 -> 分组卷积 -> 逐点卷积降维
残差连接
扩张- 卷积 - 压缩
Linear
作用等同于1×1逐点卷积,实现线性映射
ViT - CVPR 2020/10
Vision Transformer - Patching
化为互不重叠的区域,输出通道数为Token的长度。⭐ 将image拆分为16×16×3的patch
经过Conv2D提取Token,# Token中每元素均有局部宽高及通道信息
所有标记之间的盲目相似性比较
PVT - ICCV 2021
Pyramid Vision Transformer A Versatile Backbone for Dense Prediction without Convolutions
创新点:在ViT(patch embed大小固定)基础上,仿照CNN网络的特征图变化
⭐使用“渐进”收缩策略通过补丁嵌入层来控制特征图的尺度
CNNs: 特征图变化 通道×2,宽高÷2
ViT: patch embed不变
PVT: 渐进式缩小特征图,减少token数量
PVT框架:
①特征图 - patch_embed -> token
token map -> token -> token map
⭐proj = Conv2d(in_channel, dim_token[i], kernel_size[i], stride[i])
dim_token = [64, 128, 256, 512]
kernel_size = [4, 2, 2, 2]
stride= [4, 2, 2, 2] @ 渐进式缩小特征图 – 融合局部token的感觉
token数量⬇,token维度⬆(信息更加丰富)
多次Patch Embed
②Transformer Encoder 对 token 进行信息提取
-
MHSA处进行调整:引入Spacial Reduction操作
-
Spacial Reduction:将token折叠回特征图,使用Conv2d对特征图进行局部信息融合的处理,再保持通道维度不变的情况下,缩小宽高空间大小,再拆分成token,减少token数量。
对Token Key和Value的部分进行SR处理,shape=(*num_token, dim_token)
Query shape=(num_token, dim_token)
α = softmax(Q@SR(K).T / √d) shape=(num_token, *num_token)
α@V shape=(num_token, dim_token)
⭐图示操作:
利用conv局部性,将相邻的Token进行合并 | 或者利用Pool进行窗口内Token合并 (图示稍微有点问题)
计算量降低sr_ratio平方倍 – Conv2D中的stride
③将token折叠回特征图
CvT - ICCV 2021
CvT: Introducing Convolutions to Vision Transformers
很像PVT - 前置论文Bottle neck Transformer @ 在resnet末尾将后三层Conv3×3替换为MHSA (Conv结构中引入Attension全局建模)
目的:
①将卷积神经网络 (CNN) 的理想特性引入 ViT 架构(即移位、尺度和失真不变性),同时保持 Transformer 的优点(即动态注意力、全局上下文和更好的泛化)
②将具有图像域特定归纳偏差的卷积引入 Transformer 来实现两全其美
③空间维度下采样,通道增加。Token数量少了,但每个Token变长了,增强了携带信息的表示的丰富性
⭐删除位置嵌入:为每个 Transformer 块引入卷积投影,并结合卷积令牌嵌入,使我们能够通过网络对局部空间关系进行建模。使其具有适应需要可变输入分辨率的各种视觉任务的潜在优势。
Convolutional Token Embedding
重叠式的嵌入,使用标准Conv2D
并且在每个Stage最后,将Token集合折叠回Token Map
Convolutional Projection – Conv生成QKV 而非通常的nn.Linear
利用 分组卷积 将K与V的Token Map下采样,性能换效率
局部空间上下文的附加建模,相比于普通卷积(更复杂的设计和额外的计算成本),DWConv性价比更高
(b): 可参考MobileViT,先利用卷积局部融合信息,再执行窗口级注意力
Swin - ICCV 2021
Swin transformer: Hierarchical vision transformer using shifted windows
层级式ViT
创新点:
①patch embed尺寸逐步增大,检测小目标更好
总体结构
窗口级的Token特征融合操作: Swin Transformer Block 数量为偶数
①窗口内的Token信息融合
MHSA限制在窗口内进行 – 降低计算复杂度
②窗口间的Token信息融合 – 滑动窗口策略 – 间接看到全局信息
蓝线表示窗口内Token信息融合,红线表示窗口间信息融合
❗❗❗⭐⭐⭐MHSA依然限制在窗口内进行
❗为了规整统一窗口大小,便于批量计算
进行一次循环位移,使窗口大小统一
⭐使用window-mask将本该不进行自注意计算的部分遮挡掉,在计算注意力α时,在其中softmax中,将mask的值设为-100,则e^{-100} / Σ e^{i} 为 0
滑动窗口Mask示例:
给窗口编号,再使用torch.roll 滑动 ( window_size // 2 ) 个像素
$$
\text{softmax}(z)i = \frac{e^{z_i}}{\sum{j=1}^{K} e^{z_j}}, \quad \text{for } i = 1, 2, \ldots, K
\\e^{-100} ≈ 0
$$
相对位置编码:
因为计算Window-MHSA是并行的,没有位置顺序信息
⭐注意力权重 加上 相对位置偏置
✨相对位置信息 – 压缩&复用
① relative position bias table 自学习的位置标量偏置 – 压缩
② relative position bias index 索引 – 不同位置的token使用相同的相对位置偏置 – 复用
给定窗口大小,index是固定值,table是可学习的位置信息
一维情况:
Patch Mergeing
目的: 宽高减半,通道翻倍
整幅特征图分4部分,合并不同部分,相同位置的Token
Mobilevit - CVPR 2021
title: Mobilevit: light-weight, general-purpose, and mobile-friendly vision transformer
在资源受限设备上运行ViT – 混合CNN和Transformer
MV2: MobileNetv2 中的倒残差块

⬇2: 下采样2倍,控制stride步幅
MobileViT Block: – 间接融合
用二维卷积局部融合(重叠区域),输出的特征图中每个像素都会看到 MobileViT 块中的所有其他像素
红色像素使用变压器关注蓝色像素
由于蓝色像素已经使用卷积对有关相邻像素的信息进行了编码,因此红色像素可以对图像中所有像素的信息进行编码
unfold和fold 将特征图转为Token集合,改排序,不等于patch embed(用conv2d)
原论文 最后的通道维度融合,使用的Conv3x3卷积。 # 模块对称。
CrossViT - ICCV 2021
CrossViT: Cross-Attention Multi-Scale Vision Transformer for Image Classification
双分支 - 多尺度patch嵌入
互换分支的CLS Token 实现分支间的信息通信
DeiT - CVPR 2021
Training data-efficient image transformers & distillation through attention
⭐纯Transformer版本的知识蒸馏
引入distillation token来进行知识蒸馏,执行的目标不同。一个与label计算loss,一个与Teacher label计算蒸馏损失。反向传播优化时,梯度不一样
T2T - ICCV 2021
Tokens-to-Token ViT: Training Vision Transformers from Scratch on ImageNet
重叠嵌入,信息更全面。融合Token,删除冗余
soft split 重叠融合(图示是堆叠在通道维度)
BiFormer - CVPR 2023
BiFormer: Vision Transformer with Bi-Level Routing Attention
一种动态的、查询感知的稀疏注意力机制。 关键思想是在粗糙区域级别过滤掉大部分不相关的键值对,以便只保留一小部分路由区域,再进行细粒度的注意力计算
路由方式建立跨窗口信息交互
通过化为window,各Token均值为代表整window的Token,计算区域相似性关系图,借此为窗口间链接通信
将窗口串起来
DWConv 3×3 作用:
在开始时使用 3×3 深度卷积来隐式编码相对位置信息。
SMT - ICCV 2023
Scale-Aware Modulation Meet Transformer
“模拟随着网络变得更深而从捕获局部依赖关系到全局依赖关系的转变“(串行渐变结构) =联想到=> 浅层网络捕获形态特征,深层部分捕获高级节律特征
SMT1D 生硬的训练ECG 中等效果,但计算量小!
层级式ViT结构
Evolutionary Hybrid Network
结构取名为“进化混合网络” Evolutionary Hybrid Network - 局部到全局建模的过渡
SAM Block
Multi-Head Mixed Convolution
将通道分割为多个头(组),每个头使用不同大小的卷积核(目的:捕捉多个尺度的各种空间特征。增强网络的建模能力“局部远程依赖”)
例:
Scale-Aware Aggregation
倒残差结构 - 融合通道
在MHMC结构中,多头由于卷积核大小不同,更大的卷积核看到的感受野更大。 将多头各个卷积依次打包成组,进行组间通道融合,每组既有小感受野的信息,又有大感受野信息,多样 multi-scale
可视化模块效果 – 画的卷积调制权重
深度可分离卷积作为注意力权重
① 每个不同的卷积特征图都学习以自适应方式关注不同的粒度特征
②多头更准确地描绘前景和目标对象
③网络变深,多头仍然可以呈现目标物体的整体形状。与细节相关的信息在单头卷积下会丢失
⭐⭐表明 MHMC 在浅层阶段有能力比单头更好地捕获局部细节,同时随着网络变得更深,保持目标对象的详细和语义信息。
增强了语义相关的低频信号,精确地聚焦于目标对象最重要的部分。
更好的捕获和表示视觉识别任务的基本特征的能力。
Conv2Former - CVPR 2022
Conv2Former: A Simple Transformer-Style ConvNet for Visual Recognition
创新点: 用卷积操作 模拟近似 注意力 – 更低的计算代价 略低的性能下降
Hadamard product == 矩阵按元素相乘
使得每个空间位置(h,w)能够与以(h,w)为中心的k×k正方形区域内的所有像素相关。通道之间的信息交互可以通过线性层来实现。
※重点: ConvNeXt中表明,卷积核不是越大越好,超过7x7,计算代价远远大于性能收益
⭐本文实验提出,将卷积特征作为权重,能比传统方式更有效地利用大内核
ConvNeXt - CVPR 2022
ConvNeXt
将CNN搭建成SwinT的风格,性能超越SwinT
InceptionNext
多尺度版本的ConvNeXt
Shunted SA - CVPR 2022
Shunted Self-Attention via Multi-Scale Token Aggregation
PVT 和类似的模型往往会在这种空间缩减中合并太多的标记,使得小物体的细粒度信息与背景混合并损害模型的性能;
同时保留粗粒度和细粒度的细节,同时保持对图像标记的全局依赖性建模;
- 观察到PVT和ViT在同一个Encoder中token尺度是固定的,创新结合二者。用Conv将Token Map局部融合成多幅Token Map,使每个汇聚的Token代表着不同区域,不仅观察到小物体,也能看到大物体。
ViT:小区域
PVT: 大区域
Shunted : 结合大小区域
灵感源于:
做法:
不同头的长度不同,以捕获不同粒度的信息。
原始特征图x,卷积局部融合得到x1, x2 (HW均变小)
❗注意:Q的线性映射维度不变,而不同尺度的KV通过线性映射时维度缩减率为SR特征图的数量(QKV维度一致)
两种做法
细粒度 - pixel token || 粗粒度 - patch token
GC-ViT - ICML 2023
Global Context Vision Transformers
与SwinT的区别:
- 不通过滑动窗口实现全局信息建模 => 直接生成全局信息Token,使用这组携带全局信息的TokenSet来实现全局信息建模
- SwinT 层数堆不够的话,全局信息建模不强
与SwinT的共同点:
-
都属于window-wise attention
-
位置编码都采用相对位置偏置bias
-
基本单元:局部窗口内计算 + 全局信息建模;(窗口内 + 窗口间)
思路:
Global query tokens generation
MBConv - FeatureExtract
代码分析
1X: [batch, num_token, dim_token]
2x-window: [batch*num_windows, num_token//num_windows, dim_token]
3x-window-head:[batch*num_windows, num_heads, num_token//num_windows, dim_token//num_heads]
4
5
6Query: [batch × num_window, num_heads, num_tokens, dim_head]
7Key-Global: [batch, repeat , num_heads, num_tokens, dim_head]
图示最后的复制,是让每个窗口内的token与全局token表示进行信息融合 (复制窗口维度的大小)
funny: 公司{多部门} => [部门内部成员进行讨论] => [部门之间领导进行讨论]
Token Sparsification - CVPR 2023
Making Vision Transformers Efficient from A Token Sparsification View
动机:
*观察到注意力后期,仅部分核心Token起着主要作用*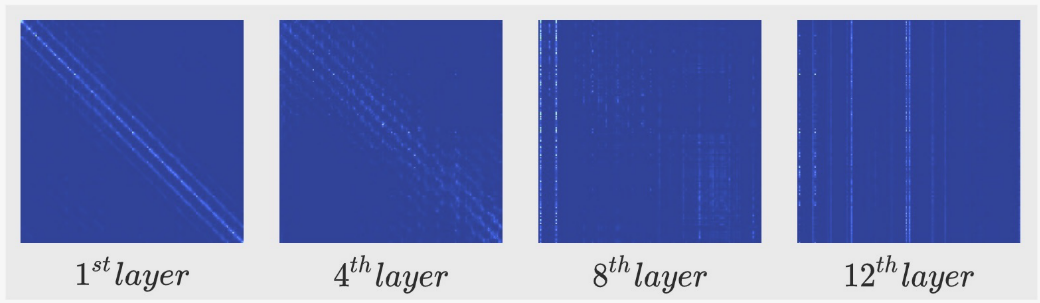
对Token进行瘦身 - 与利用CLS Token进行级联删除不用的策略
方法: Sparse Token Vision Transformer
Semantic Token Generation Module
1️⃣ Base Module 学习浅层特征
2️⃣ 进行Spatial Pooling聚合区域,生产空间簇中心TokenSet
**Conv( GELU( LayerNorm( DWConv( X ))))** *- 深度可分离*
创新:**Intra and inter-window** spatial pooling
目的:聚合窗口信息(代表) + 疏远窗口间信息(不可被替代)
3️⃣ 融合生成Semantic Token Set - Global Initial Center G 是可学习的参数 $$ \overline{S^{1}} = MHA(P, X, X) + P,\ \ \ S^{1} = FFN(\overline{S^{1}}) + \overline{S^{1}} \\ \overline{S^{2}} = MHA(S^{1} + G, Concat(S^{1}, X), Concat(S^{1}, X)) + P,\ \ \ S^{2} = FFN(\overline{S^{2}}) + \overline{S^{2}} \ S^{2} = Semantic\ \ Token $$
Recovery Module
$$
\overline{X} = MHA(X, S, S) + P,\ \ \ X = FFN(\overline{X}) + \overline{X}
$$
融合操作的逆过程
从语义级TokenSet中恢复空间信息
First layer attention maps
HiLo Attention - NeurIPS 2022
Fast Vision Transformers with HiLo Attention
图像中的高频捕获局部精细细节,低频关注全局结构,而多头自注意力层忽略了不同频率的特征。 因此,我们建议通过将头部分为两组来解开注意力层中的高频/低频模式,其中一组通过每个局部窗口内的自注意力对高频进行编码,另一组通过在每个局部窗口内执行全局注意力来对低频进行编码,输入特征图中每个窗口和每个查询位置的平均池化低频键和值。
创新点:
- 将自注意力分为高频和低频
- 高频捕捉局部精细细节(轮廓、边缘)
- 低频捕获整体结构or趋势
- high部分是window级别的attn
- low部分是space reduce(经过pool)的粗糙级别的attn
图示:
伪代码:
1HiLoAttention():
2 def high(x):
3 # window-partition
4 [batch, num_token, dim_token] => [batch, num_window, window_size, dim_token]
5 # multi-head
6 [batch, num_window, window_size, dim_token] => [batch, num_window, num_head, window_size, dim_head]
7
8 # do attention
9 # reshape to restore
10
11 def low(x):
12 B, L, C = x.shape
13 x_ = x.transpose(-2, -1) # [batch, channel, length]
14 x_ = self.sr_cnn(x_) # [batch, channel, _length] reduce length || avgpool or dwconv
15
16 q = self.q(x).reshape() => [batch, num_head, num_token, dim_head]
17 k, v = self.kv(x).reshape()[...] => [batch, num_head, *num_token, dim_head]
18
19 # do attention
20 # reshape to restore
21
22 def forward(x):
23 x1 = high(x)
24 x2 = low(x)
25
26 x = torch.cat([x1, x2], dim=-1)
27 x = self.proj(x)
CMT - CVPR 2022
CMT: Convolutional Neural Networks Meet Vision Transformers
注重点:与之前基于 CNN 和基于 Transformer 的模型相比,在准确性和效率方面获得了更好的权衡。
⭐ 由于 patch 大小固定,Transformer 很难显式地提取低分辨率和多尺度特征 => 图像是二维的(即具有宽度和高度),并且在图像中的每个像素位置都与其周围的像素有关。这种空间局部信息非常重要,例如,边缘检测、纹理分析等都依赖于这种局部关系。=> Patchfiy 后削弱了pixel之间的关系,只补充了Patch间的位置信息。
CNN、Transformer 、CNN&Transformer
在每个阶段,产生层次表示 – 金字塔结构
- 定制的Stem
- Block内部混合CNN和MHSA ❤️ [DWConv(Skip-con) + SR-MHSA(Skip-con) + IRFFN(Skip-Conv)]
Conformer - 2020
Conformer: Convolution-augmented Transformer for Speech Recognition
集成了 CNN 和 Transformer 组件以进行端到端识别的架构
分析:
- 虽然 Transformer 擅长对远程全局上下文进行建模,但它们提取细粒度局部特征模式的能力较差;
- 卷积神经网络(CNN)利用局部信息,在本地窗口上学习共享的基于位置的内核,能够捕获边缘和形状等特征。使用本地连接的限制之一是需要更多的层或参数来捕获全局信息。
⭐ 将卷积与自注意力有机结合起来。 我们假设全局和局部交互对于参数效率都很重要。 为了实现这一目标,我们提出了一种自注意力和卷积的新颖组合,将实现两全其美
architecture
Convolution Module
Feed Forward Module
PathFormer - ICLR 2024
PATHFORMER: MULTI-SCALE TRANSFORMERS WITH ADAPTIVE PATHWAYS FOR TIME SERIES FORECASTING
architecture
Dual-Attention
Mobile-Former - CVPR 2022
Mobile-Former: Bridging MobileNet and Transformer
动机:
-
如何设计高效的网络来有效地编码本地处理和全局交互?
-
最近工作:串联组合卷积和视觉变换器的好处,无论是在开始时使用卷积还是将卷积交织到每个变换器块中
-
视觉变换器(ViT)[10,34]展示了全局处理的优势,并实现了比 CNN 显着的性能提升,如何在计算资源或者参数量有限的情况下充分挖掘结合两者的优势,=> parameters efficient
贡献:
- 并行设计 + 双路桥接; 利用了 MobileNet 在本地处理和 Transformer 在全局交互方面的优势;实现局部和全局特征的双向融合
- 全局Token只有初始化为0的很少的Token,利用Cross Attention 进行交互
- ⭐大概就是在MobileNet为主干的基础上添加ViT全局Token的信息注入
architecture
Interaction
pseudo code
1q = FC(token).view(), k, v = x.view() # shape => batch, num_token, dim_token;
2do Local2Global-CrossAttn()
3
4token => MHSA()
5
6x = MobileNetBlock()
7
8q = x.view(), k, v = FC(token).view()
9do Global2Local-CrossAttn()
ViT Adapter - ICLR 2023
VISION TRANSFORMER ADAPTER FOR DENSE PREDICTIONS
动机
-
在不改变原有ViT的基础上(利用大规模预训练参数),添加辅助器帮助Transformer学习弱项;【使用现成的预训练 ViT 适应密集的预测任务】
-
ViT 单尺度和低分辨率表示的弱点 => 注入一些多尺度特征(CNN)给单尺度的ViT
…表明卷积可以帮助 Transformer 更好地捕获局部空间信息,对与补丁嵌入层并行的图像的局部空间上下文进行建模,以免改变 ViT 的原始架构。
贡献
- ViT Adapter: [Spatial Prior Module, Spatial Feature Injector, Multi-Scale Feature Extractor]
paradigm compare
architecture
- (c)用于根据输入图像对局部空间上下文进行建模的空间先验模块, Adapter: Spatial feature token set; ViT: origin feature map;
- (d)用于将空间先验引入ViT的空间特征注入器
- (e)用于从单个图像重新组织多尺度特征的多尺度特征提取器 -ViT 的尺度特征
采用稀疏注意力来降低计算成本
pseudo code
1# Spatial prior module
2X_vit = ResnetBlock(x)
3x1 = PointConv(Conv(X_vit)) # down-sample: HW/8^2 and project channel to D dimension
4x2 = PointConv(Conv(x2)) # down-sample: HW/16^2 to D dimension
5x3 = PointConv(Conv(x3)) # down-sample: HW/32^2 to D dimension
6X_vit = torch.cat([x1, x2, x3], dim=num_token)
7
8# injector // spatial feature to ViT
9q = FC(X_vit).view(...), k, v = FC(X_spm).view(...) # spm: spatial prior module
10do Cross-Attn()
11
12# Multi-Scale Feature Extractor
13q = FC(X_spm).view(...), k, v = FC(X_vit).view(...) #
analyze:
- ⭐ 研究表明,ViT 呈现出学习低频全局信号的特征(整体、模糊和粗糙),而 CNN 则倾向于提取高频信息(例如局部边缘和纹理)
visualize
傅里叶变换特征图的傅里叶频谱和相对对数幅度(超过 100 张图像的平均值) => 表明 ViT-Adapter 比 ViT 捕获更多的高频信号
我们还可视化了图5(b)(c)中的stride-8特征图,这表明ViT的特征是模糊和粗糙的
Inception Transformer - NeurIPS 2022
Inception Transformer
动机:
-
Transformer 具有很强的建立远程依赖关系的能力,但无法捕获主要传达局部信息的高频;
-
ViT 及其变体非常有能力捕获视觉数据中的低频,主要包括场景或对象的全局形状和结构,但对于学习高频(主要包括局部边缘和纹理)不是很强大(CNNs很擅长,它们通过感受野内的局部卷积覆盖更多的局部信息,从而有效地提取高频表示);
-
最近的研究[21-25]考虑到CNN和ViT的互补优势,将它们集成起来。 一些方法[21,22,24,25]以串行方式堆叠卷积层和注意力层,以将局部信息注入全局上下文中。 不幸的是,这种串行方式仅在一层中对一种类型的依赖关系(全局或局部)进行建模,并且在局部性建模期间丢弃全局信息,反之亦然。❤️ 每个模块都不够全面=>模型要么只有局部感知能力,要么只有全局建模能力 => 在ECG中,有些疾病不仅仅是局部或全局的病理特征,而且是节律异常伴随着波形形态异常;从这一角度出发,我们希望能够充分的利用Transformer的全局依赖感知能力和CNN的强大的局部感知能力,交互融合有力结合两者优势; 【就像在人类视觉系统中一样,高频分量的细节有助于较低层捕获视觉基本特征,并逐渐收集局部信息以对输入有全局的理解】
-
层级式网络,多尺度分辨率特征图,每部分均能全局+局部感知;并且设计频率斜坡结构 => 底层更注重高频信息(细节信息,局部模式、纹理边缘);高层更注重低频信息(整体轮廓,全局)
创新点:
- Transformer中的Multi-Head Self-Attention => Inception Mixer ;
- 按channel分两组:1. 低频组;2. 高频组;
- 低频组 池化稀疏注意力,但仅最低两块用;
- 高频组 [MaxPool, DWConv];
- 按channel分两组:1. 低频组;2. 高频组;
- 频率斜坡结构: 高频组>低频组 => 高频组<低频组
- 底层在捕获高频细节方面发挥更多作用,而顶层在建模低频全局信息方面发挥更多作用
architecture
Inception Mixer
pseudo code
1# x : [batch, channel, width, hight]
2x_h, x_l = torch.chunk(x, chunks=2, dim=1)
3x_h1, x_h2 = torch.chunk(x_h, chunks=2, dim=1)
4
5y_h1 = FC(MaxPool(x_h1))
6y_h2 = DWConv(FC(x_h2))
7y_l = MSA(AvePooling (X_l))
8
9Y = X + ITM(LN(X)) # ITM : Inception Mixer
10H = Y + FFN(LN(Y))
局部|高频 & 全局|低频 - 傅里叶谱
TransNeXt - CVPR 2024
TransNeXt: Robust Foveal Visual Perception for Vision Transformers
analysis
- 目前的稀疏Attention:
- Local Attention[限制计算量,n×固定窗口计算量]: window-level attention, => cross-window attn information exchange 需要堆叠很深才能实现全局感知
- patially downsamples【降低计算的Token数量】: pool or dwconv => 信息丢失问题; 【细粒度(丢失)=> 粗粒度】
motivation
- ⭐ 观察:生物视觉对视觉焦点周围的特征具有较高的敏锐度,而对远处的特征具有较低的敏锐度。
- 结合window-level attn & spatial downsample attn,临近的token执行pixel-level attn,稍远的区域执行pool-level attn, 实现视觉仿生聚焦attn
contribution
-
focus attn 【局部细粒度,全局粗粒度】
-
focus attn 升级 aggregated attention 【QKV 注意力、LKV 注意力和 QLV 注意力统一】
- QLV 与传统的 QKV 注意力机制不同,它破坏了键和值之间的一对一对应关系,从而为当前查询学习更多隐含的相对位置信息。
- LKV:增强表达能力,通过引入可学习的键和值,模型可以学习到更多有用的特征,增强了对复杂关系的建模能力
-
length-scaled cosine attention 【双路注意力concat经过同一个softmax】
-
convolutional GLU替换MLP
architecture
left figure: focus attn; right figure: aggregated attn(add QKV-attn、LKV-attn、QLV-attn)
共享同一个Softmax(作用可能是这里进行多注意力的制约交互)
ConvGLU: 卷积 GLU (ConvGLU) 中的每个标记都拥有一个独特的门控信号,基于其最接近的细粒度特征。 这解决了SE机制中全局平均池化过于粗粒度的缺点。 它还满足了一些没有位置编码设计、需要深度卷积提供位置信息的ViT模型的需求。
EfficientViT - CVPR 2023
EfficientViT Memory Efficient Vision Transformer with Cascaded Group Attention
权衡性能和代价
motivation
- 发现现有 Transformer 模型的速度通常受到内存低效操作的限制,尤其是 MHSA 中的张量整形和逐元素函数;
-
虽然Transformer性能很好,但是代价很高,不适合实时应用; =>优化;
-
发现注意力图在头部之间具有高度相似性,导致计算冗余。// 显式分解每个头的计算可以缓解这个问题,同时提高计算效率
contribution
- 设计了一种具有三明治布局的新构建块,即在高效 FFN 层之间使用单个内存绑定的 MHSA,从而提高内存效率,同时增强通道通信;
- 提出了一个级联的组注意力模块,为注意力头提供完整特征的不同分割,这不仅节省了计算成本,而且提高了注意力多样性。
architecture
Token Interaction:DWConv,增强局部交互能力,引入局部结构信息的归纳偏差来增强模型能力
三明治结构中,局部建模和全局Attn, 即[Token Interaction, FFN][Cascaded Group Attention][Token Interaction, FFN]堆叠不是1:1:1, 而是N:1:N, Why? because Attention 计算量太大了,能少用就少用。
Cascaded Group Attention pseudo code
1feature_group = x.chunk(len(self.qkv_group), dim=1) # split head
2feature = feature_group[0] # first head
3
4feature_out = []
5for i, qkv in enumerate(self.qkv_group):
6 if i > 0:
7 feature = feature + feature_group[i] # Cascaded Group
8 Q, K, V = qkv(feature).view().permute() # shape: B, H, N, C/H
9 Q = DWConv[i](Q) # enhance Query Token Set
10 out = (Q@K.transpose(-2, -1) × scale)@V
11 feature_out.append(out)
12out = torch.cat(feature_out, 1)
13FC(out)
不同于传统Attn,这里先分头再线性映射,头的信息会越来越丰富。 并且实现中(Cascaded Group Attention in Window-level Attention )
EMO - ICCV 2023
Rethinking Mobile Block for Efficient Attention-based Models
目标:轻量级 CNN 设计高效的混合模型,并在权衡精度、参数和 FLOP 的情况下获得比基于 CNN 的模型更好的性能
出发点:我们能否为仅使用基本算子的基于注意力的模型构建一个轻量级的类似 IRB 的基础设施?
基本算子结构对比
-
Multi-head self attention: 线性映射qkv,MHSA, 投影回来
-
Feed Forward Network: Linear-Linear
-
Inverted Residual Block: Conv1x1-DWConv-Conv1x1
=> 综合考量 提出基本算子Meta Mobile Block
Meta Former Block vs Inverted Residual Block
更加细致的抽象
iRMB(Inverted Residual Mobile Block)
-
!!! 由于 MHSA 更适合对更深层的语义特征进行建模,因此我们仅在之前的工作之后的 stage-3/4 中打开它 。
-
Conv:
- BN+SiLU与DWConv结合;
-
W-MHSA(window-level attention 更加高效):
-
LN+GeLU与EW-MHSA结合。
-
解释EW-MHSA
- 因为iRMB,会先升维,导致MHSA计算量变高, Q,K维度不变,而V的维度变长了,拿attn-score加权求和时应用的是扩展V
-
深度设计,灵活的设计
Focal Attention - NeurIPS 2021
Focal Attention for Long-Range Interactions in Vision Transformers
观察:
图 1:左:DeiT-Tiny 模型 [55] 第一层中给定查询块(蓝色)处三个头的注意力图的可视化。 右图:焦点注意力机制的说明性描述。 使用三个粒度级别来组成蓝色查询的注意区域。
创新点:
- Close => Far
- Fine => Coarse
图示:
伪代码:
11. 使用torch.roll 再按窗口划分 => 收集细粒度周边Token, 再使用mask掩码掉多余不需要的Token
22. 先分窗口,执行窗口内Pool,生成超粗粒度Token
3
4Q: 窗口内Token
5K, V: 窗口内Token + 周边细粒度Token + Pool-Token
CloFormer - CVPR 2023
Rethinking Local Perception in Lightweight Vision Transformer
architecture
局部+全局 感知并行
局部感知,类似于CNN中的卷积注意力用在自注意力分支中
FFN 内追加局部感知增强模块
MetaFormer - 2023
我们并不试图引入新颖的令牌混合器,而只是将令牌混合器指定为最基本或常用的运算符来探测 MetaFormer 的能力
⭐探索Meta Block的潜力!
1X = X + TokenMixer(Norm(X))
2X = X + ChannelMixer(Norm(X))
MaxViT - ECCV 2022
MaxViT: Multi-Axis Vision Transformer
动机:解决Self-Attention平方复杂度问题
框架:
1️⃣ MobileNetV2中的倒残差块 => 提供增强局部感知 & 隐式编码位置信息
2️⃣ Block-Attention => window-level attention ❌ 限制感受野 ⭐ 降低计算量
3️⃣ Grid-Attention => 感受野遍及全局的扩张卷积做法 1. 分窗口 2. 收集每个窗口相同次序的Token成组. 3. 组内计算注意力
Attention illustration
CiT - ICCV 2021
Incorporating Convolution Designs into Visual Transformers
局部增强
就是Inverted Resiual Block [Conv1×1 => Depth-wise Conv3×3 => Conv1×1] 对Token进行局部信息增强
框架:
⭐利用了每个Stage中的Class Token,这样可以有层级式信息,而且梯度会通过这个CLS Token直接传递给前面部分
Bi-Interaction Light-ViT
Lightweight Vision Transformer with Bidirectional Interaction
图示:
框架:
⭐想法很超前⭐
局部与全局的相互调制
UniRepLKNet
UniRepLKNet: A Universal Perception Large-Kernel ConvNet for Audio, Video, Point Cloud, Time-Series and Image Recognition
⭐超大卷积核 Conv winwinwin
当我们向小内核 ConvNet 添加 3×3 卷积时,我们期望它同时产生三种效果
- 使感受野更大,
- 增加空间模式的抽象层次(例如,从角度和纹理到物体的形状)
- 通过使其更深,引入更多可学习的参数和非线性来提高模型的一般表示能力
相比之下,我们认为大内核架构中的这三种影响应该是解耦的,因为模型应该利用大内核的强大优势——能够看到广泛而不深入的能力
由于在扩大 ERF(感受野) 方面,增加内核大小比堆叠更多层更有效,因此可以使用少量大内核层构建足够的 ERF,从而可以节省计算预算以用于其他高效结构 在增加空间模式的抽象层次或总体上增加深度方面更有效。
框架:
重参数化
块设计
EdgeViTs - ECCV 2022
EdgeViTs: Competing Light-weight CNNs on Mobile Devices with Vision Transformers
架构:
# 类似MobileViT
1X = LocalAgg(Norm(X)) + X #
2Y = FFN(Norm(X)) + X
3Z = LocalProp(GlobalSparseAttn(Norm(Y))) + Y
4Xout = FFN(Norm(Z)) + Z
图示: (选举 => 精英 => 分发)
ShuffleNet - CVPR 2018
出发点:构建高效模型
⭐V1⭐
缺点发现:
1=> Conv1x1 _ Norm+ReLU # Point-wise
2=> DWConv3x3 _ Norm # Depth-wise
3=> Conv1x1 _ Norm+ReLU # Point-wise
4
5# 为了高效 => 只是将Conv3x3 => Conv1x1
6# => 但是Conv1x1占据了93.4%的乘法-加法
7
8# => 目标,优化PWConv
操作图示:
卷积分组减少计算量 (⭐优化组间通信⭐)
ShuffleNet Basic Block
- (a) ResNet bottleneck unit <= DWConv
- (b) 优化PWConv(Group Conv),并且Channel Shuffle,执行Group communication # 无下采样,输入输出shape一致
- (c) 恒等映射占据一半的Channel,另一半精修过的Feature Map
⭐V2⭐
=> 分析各个类型操作占据的计算成本
除了FLOPS指标,吞吐量和速度更为直接直观,符合真实贴切
(使用FLOP作为计算复杂性的唯一度量是不够的,并且可能导致次优设计)
(具有相同FLOP的操作可能具有不同的运行时间)
- 访存时间 <=
- 并行度 <=
- (a) basic shuffle net block -v1
- (b) basic shuffle net block with downsample -v1
- (c) v2
- (d) v2 with downsample
1# shape equivalence
2x.shape = (B, 64, H, W)
3x1, x2 = channel-split(x) # => (B, 32, H, W), (B, 32, H, W)
4# x1 作为恒等映射,残差连接? 特征复用?
5out = concat(x1, block(x2))
6out = channel-shuffle(out)
7
8# with downsample
9x.shape = (B, 64, H, W)
10x1, x2 = x, x # => (B, 64, H, W), (B, 64, H, W)
11out = concat(branch1(x1), branch2(x2))
12out = channel-shuffle(out)
特征复用示意图:
$$
l1-norm = \sum_{i=1}^n{|v_i|}
$$
相邻层更高效
准确率参数贡献✔️
RepVGG - ReParams - CVPR 2021
结构分析
内存分析:
=> 权衡:性能和计算内存成本
Train:多分支结构,性能好
Test: 单分支结构,速度快,内存少
⭐⭐⭐重参化:
细节:
举例第一个卷积后的元素
Agent Attention - ECCV 2024
Attn图示:
做法:
code:
1q, k, v = qkv[0], qkv[1], qkv[2]
2
3agent_token = pool(q)
4
5agent_attn = softmax(agent_token * scale @ k.T + position_bias)
6agent_v = agent_attn @ v
7
8q_attn = self.softmax((q * self.scale) @ agent_tokens.T + agent_bias)
9x = q_attn @ agent_v
10
11x = x + self.dwc(v)
12
13
14# 复杂度
15o(N * K) + o(N * K)
享受 => 高表达性和低计算复杂度的优势
CF-ViT
CF-ViT: A General Coarse-to-Fine Method for Vision Transformer
对于分类任务 - 不需要那么精细的patch
两步策略:
- 粗粒度patch=>ViT => 预测得分 =若得分小于设定的置信度> 将重要区域细分 =ViT> 最终预测
特征复用
- 不重要区域 => 大尺度粗略的Patch (可能有不相关的背景干扰)
- 重要区域 => 小尺度精细的patch(更多边缘细节) <= 第一阶段粗略的Patch充当区域嵌入
利用ViT中[CLS] Token与其他Token的Attn累计区域的重要性
Global-Attn = αAttn_l + (1-α)Attn_l+1
Training
loss = CE(pf, y) + KL(pc,pf)
训练时每次均进行Patch精细推理。使用精细模型指导粗略Patch推理
Conformer: ResNet + ViT
并行结构 => 同时保留局部和全局特征 (保持CNN和ViT架构的优势)
Twins: [Local-Global]
[LSA-FFN] => [GSA-FFN]
window-self-attention => global-self-attention
MSG-Transformer
架构
有趣点 - Shuffle-Net ?
局部信使 - 传递信息
DilateFormer
IEEE TRANSACTIONS ON MULTIMEDIA – sci-1
overview
novel
不同注意力头部,进行细微的调整
ScopeViT
Pattern Recognition
Architecture
novel
串行交叉:[多尺度, 多份KV]+[dilated Attention]
$$
𝐐 = 𝑋𝐖_𝑄,𝐊_𝑖 = 𝑃_𝑖𝐖^𝐾_𝑖, 𝐕_𝑖 = 𝑃_𝑖𝐖^V_𝑖
$$
1 Query不变, KV通过多个不同内核大小的DWConv生成多尺度 KV (粗粒度)
2 Stride Attention (细粒度)
FastViT - ICCV
overview
Stem:
1reparams-conv
前三阶段:
1x = x + BN(DWConv(X)) # re-params
2x = x + (DWConv->BN->Conv1x1->GELU->Conv1x1) # ConvFFN
最后阶段:
1x = x + DWConv(X) # CPE convolution position embedding
2x = x + BN(Attention(X)) # Attention
3x = x + (DWConv->BN->Conv1x1->GELU->Conv1x1) # ConvFFN
Integration of CNN + Attention
Revisiting the Integration of Convolution and Attention for Vision Backbone
novel
1Conv-part: [Conv1x1->DWConv5x5->Conv1x1] => X_conv # ConvFFN ?
2Attn-part:
31. [聚簇] Clustering:X -> pooling -> cluster
42. [提炼] cluster@X.T -> score@X -> cluster$ {这里用点积相似度举例}
53. [全局] cluster$ -> MHSA -> cluster$
64. [分发] cluster$ -> cluster@score.T => X_attn
7
8Y = X_conv + X_attn
RepNeXt
overview
1Token-Mixer:
2 1. nn.Identity()
3 2. DWConv3x3 + (DWConv1x3 + DWConv3x1)
4 3. DWConv7x7 + DWConv3x5 + DWConv5x3 + (DWConv1x5 -> DWConv5x1) + (DWConv1x7 -> DWConv7x1)
5 4. (DWConv1x11 -> DWConv11x1)
6
7nn.Conv2d(in_channels, out_channels, kernel_size=(3, 5), padding=(1, 2), bias=bias, stride=stride)
8# Fusion => 重参数化融合
InceptionNeXt
1Block: [Token-Mixer -> Norm -> FFN]
2025/1/14 Tidying up
ViT with Deformable Attn
Vision Transformer with Deformable Attention
全部采样点如下:
高得分key采样点如下
1# 1. 生成 query
2q = Conv1x1(X)
3offset = ConvKxK(q).conv1x1()=> // 将通道映射为2,并且为了提高采样点的多样性,将通道分组,每组获取不一样的信息。
4reference = 规整的网格
5pos = reference + offset // 固定点 + 偏移
6x_sampled = F.grid_sample(X, pos)
7
8k = Conv1x1(x_sampled)
9v = Conv1x1(x_sampled)
10
11MHSA(q, k, v)
⭐⭐⭐
PVT下采样技术导致严重的信息丢失❗,而Swin-T的shiftwindow注意力导致感受野的增长要慢得多❗,这限制了对大型物体建模的潜力。Deformable DETR已经通过在每个尺度上设置Nk = 4的较低数量的键来减少这种开销,并且作为检测头工作良好,但是由于不可接受的信息丢失,在骨干网络中关注如此少的键是不好❗
这不就是步幅Attention,添加了可变嘛